
Why Your GTM Has No Brain and How to Fix It
58% of AEs miss quota. Sales cycles are up. The fix isn't more AI tools—it's architecture. Learn the 6-layer system that creates compound intelligence

Blockbuster had more stores. More employees. More capital.
None of it mattered.
Netflix won because they understood something Blockbuster couldn’t see: the value wasn’t in physical distribution. It was in knowing what you wanted to watch before you knew it yourself.
That same moment is happening right now in go-to-market.
But instead of physical vs. streaming, it’s scattered knowledge vs. unified context.
Only 58% of ramped Account Executives are hitting quota. Sales cycles have extended by 3-4 weeks on average since last year. Cost per opportunity for companies under $25M ARR nearly doubled—from $5,500 to $10,000. And conversion to Closed-Won deals is down 5-10 percentage points year-over-year.
Meanwhile, AI-Native companies are converting free trials at 56% versus 32% for traditional SaaS companies.
Most companies are responding by adding more AI tools. More copilots. More chatbots. More automation.
They’re solving the wrong problem.
I’ve spent 21 years building growth systems at companies from pre-revenue to $15B. I’ve seen a lot of “transformations” that weren’t. But what’s happening right now in go-to-market? This is different. This is the kind of shift that creates trillion-dollar winners and destroys companies that can’t adapt fast enough.
And most organizations are completely unprepared for it.
The GTM Crisis Is Real—and Getting Worse
The 2025 data is unambiguous:
CAC payback periods have plateaued at approximately 16 months for top quartile companies—up from under 12 months pre-2020. Pipeline coverage has declined from 3.9x to 3.6x year-over-year. Net magic number has trended down over the past two years, with companies under $100M ARR dropping from 1.5x pre-2020 to just 0.7x-1.0x in 2025.
The funnel is breaking at every stage. Top-of-funnel conversion remains relatively flat, but companies are having a harder time turning late-stage opportunities into closed deals. Demo-to-Closed-Won conversion dropped from 40% to 35% for sub-$25M companies in just one year.
I’ve sat in hundreds of boardrooms watching executives debate whether the problem is messaging, pricing, market timing, or team performance. They’re asking the wrong question entirely.
The problem isn’t your people. It isn’t your product. It isn’t even your strategy.
The problem is that your go-to-market operation has no nervous system.
What I Mean by “Nervous System”
Your body’s nervous system does something remarkable: it captures millions of signals every second, recognizes patterns, applies context from past experience, coordinates complex responses, and gets smarter from every interaction—all without you having to consciously think about it.
When you touch a hot stove, you don’t convene a committee meeting to discuss the appropriate response. Your system senses, processes, decides, and acts in milliseconds. And critically, it remembers—so you’re less likely to touch that stove again.
Now think about your GTM operation.
80% of companies report active experimentation or implementation of internal AI tools across workflows. Yet 85% of AI projects still fail to deliver their promised value, and only 33% of marketing technology investments are actually being utilized.
This isn’t a tooling problem. It’s an architecture problem.
When a prospect visits your pricing page three times in one day, does your system automatically recognize the buying signal, pull relevant context from similar patterns, and coordinate the optimal response? Or does that signal sit in a database somewhere while your team manually pieces together what’s happening days later?
When a customer shows early signs of churn—signs that might match patterns from dozens of previous churns—does your system surface that insight proactively? Or do you learn about it in a quarterly business review after it’s too late?
When a sales rep closes a deal using a discovery approach that dramatically outperforms all others, does that pattern automatically propagate across your entire team? Or does it stay locked in that rep’s head until they leave for your competitor?
Most companies have what I call “pattern blindness”—they’re generating enormous amounts of data but can’t see the patterns hidden inside it. And every day that goes by, that pattern blindness compounds into permanent competitive disadvantage.
The Six Layers That Change Everything
After studying successful AI-native transformations—the ones that actually worked versus the ones that became expensive experiments—a clear architecture emerges. I call it the Revenue Nervous System, and it has six distinct layers that work together to create compound intelligence.
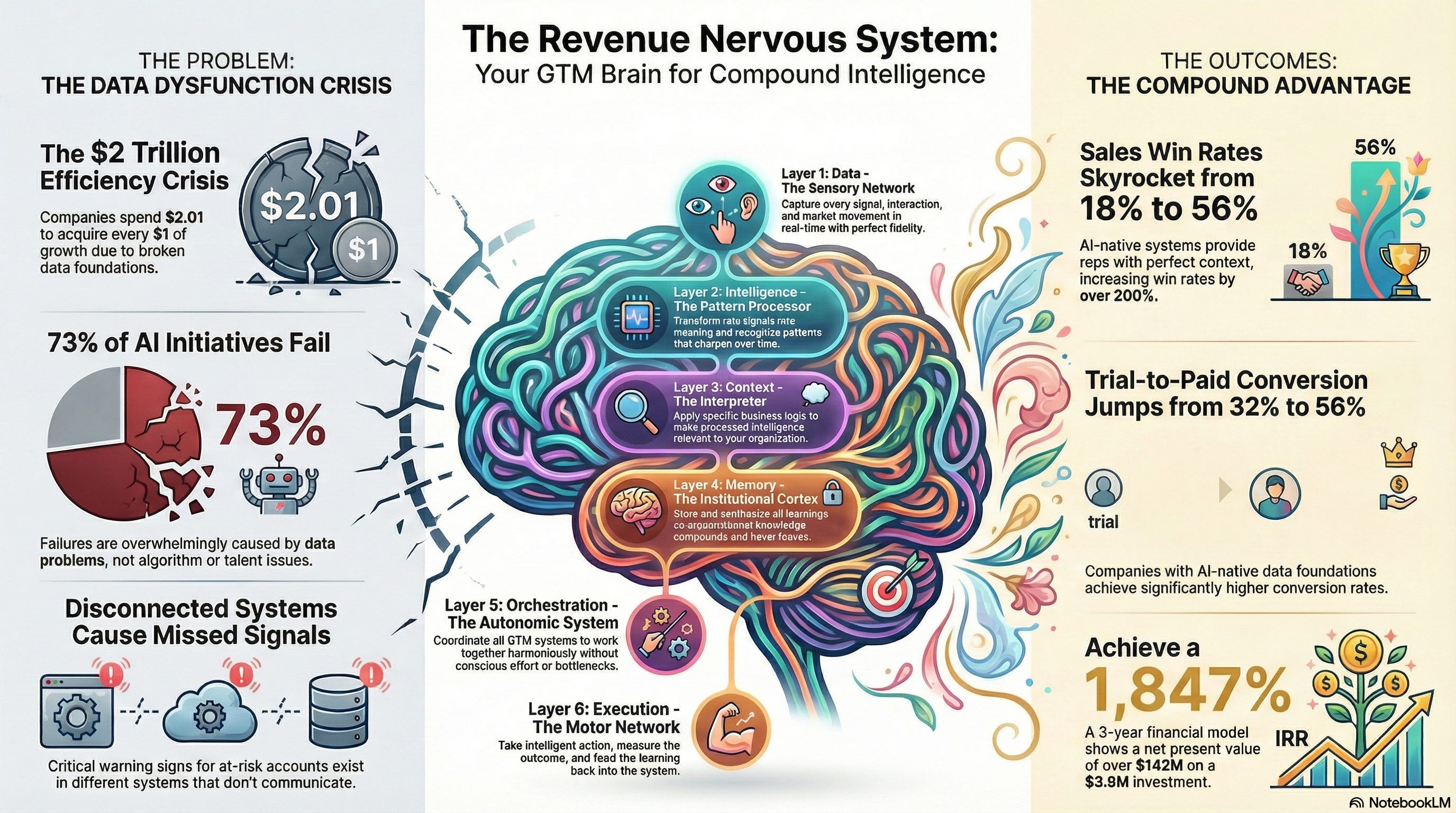
Layer 1: Data (The Sensory System)
This is where most companies start and stop. They connect their CRM, maybe add some intent data, perhaps integrate product usage signals. But true AI-native data infrastructure captures every signal: website behavior, email engagement, social activity, support interactions, competitive intelligence, market indicators. All flowing in real-time. Think of it as your revenue operation’s sensory neurons—if you can’t sense the signal, you can’t respond to it.
Layer 2: Intelligence (The Pattern Engine)
Here’s where it gets interesting. This layer doesn’t just collect data—it recognizes patterns. It can identify which deal characteristics predict faster close rates, discover which customer behaviors precede churn, spot that your best customers share characteristics you’ve never explicitly defined. This is the brain’s visual cortex—transforming raw signals into meaningful patterns your organization can act on.
Layer 3: Context (The Business Logic)
Raw patterns aren’t enough. Your system needs to understand your business: your ICP definition, your competitive positioning, your pricing strategy, your market focus. The Context Layer applies organizational knowledge to intelligence, filtering what matters from what doesn’t. A buying signal from your ideal customer segment gets treated differently than the same signal from outside your target market.
Layer 4: Memory (The Institutional Knowledge)
This is the layer most companies completely miss—and it’s the one that creates compound advantage.
Your most important data doesn’t live in a database. It lives in Slack threads, deal desk calls, and the tribal knowledge passed between employees. “We always give healthcare companies an extra 10% because their procurement cycles are brutal.” That rule isn’t in your CRM. When the person who knows it leaves, it walks out the door.
Foundation Capital calls this the “decision trace” problem. Rules tell you what should happen. Decision traces capture what actually happened—the exceptions, overrides, and cross-system context that explain why. The reasoning connecting data to action was never treated as data in the first place.
Here’s what it looks like when you solve it:
An AI agent proposes a 20% renewal discount. Policy caps it at 10%. But the agent pulls three SEV-1 incidents from PagerDuty, an open escalation in Zendesk, and a prior thread where a VP approved a similar exception.
The CRM stores one fact: “20% discount.”
A Memory Layer captures the entire story—the policy, the cross-system data, the precedent, the approval. That’s what makes it auditable. That’s what makes it compound.
I’ve come to believe Memory is the real differentiator. AI tools are commoditizing. Data is increasingly available. But institutional memory that compounds over time? That creates permanent moats.
Layer 5: Orchestration (The Coordination Hub)
Individual insights are useless without coordinated action. The Orchestration Layer translates intelligence into workflows that span multiple systems, channels, and teams. It ensures that when a high-intent signal appears, the right person takes the right action at the right time—without manual handoffs, without dropped balls, without the latency that kills deals.
Layer 6: Execution (The Action Interface)
Finally, execution. But here’s what makes it different: every action feeds back into the system. Every email opened, every meeting scheduled, every deal won or lost becomes data that strengthens every other layer. The system doesn’t just act—it learns from every action and gets smarter for next time.
Why This Isn’t “AI-Enabled” GTM
Most companies think they’re adopting AI when they add ChatGPT for content writing, implement a sales copilot, or deploy an AI chatbot.
They’re not building AI-native systems. They’re putting racing stripes on a horse.
Here’s the difference:
AI-Enabled: Your existing processes + AI tools. Departmental improvements. Human-dependent learning. Linear value creation. Temporary advantages.
AI-Native: Processes rebuilt around compound intelligence. System-wide learning. Autonomous feedback loops. Exponential value creation. Permanent competitive moats.
The 2025 data makes this distinction concrete. GTM organizations with “high AI adoption”—defined as AI fully embedded into GTM processes—are outperforming peers across nearly every sales productivity and efficiency metric:
MQL to SQL conversion: 32% vs. 27% for medium/low adopters
Free Trial to Closed-Won: 41% vs. 36%
Percentage of ramped AEs achieving quota: 61% vs. 56%
Cost per opportunity: $8,300 vs. $8,700
Late renewals: 23% vs. 25%
And here’s the leverage effect: companies under $25M ARR with high AI adoption are running leaner teams—13 GTM FTEs on average versus 21 for their peers. That’s 38% fewer people delivering better results.
The pattern isn’t limited to small companies. AI-Native companies across all revenue scales show 56% free trial/POC conversion rates compared to 32% for traditional SaaS—particularly pronounced among $100M+ ARR companies.
The difference isn’t incremental. It’s architectural.
Why Incumbents Can’t Build This
If the architecture is so valuable, why aren’t Salesforce or Workday or Snowflake already building it?
Because they’re structurally incapable of capturing what matters most.
Salesforce and Workday prioritize current state. They know what a deal looks like now—not the reasoning that justified it. The discount is in the system. The three escalations, the precedent search, the VP approval thread that made the discount defensible? Gone.
Snowflake and Databricks sit in the read path, not the write path. By the time data lands there, the decision context is already stripped away. You can analyze what happened. You can’t reconstruct why.
Capturing decision traces requires being in the execution path when decisions are made. Not bolting on governance after the fact. Not running analytics on sanitized exports. You have to be present at the moment of decision, capturing the full context that made that decision make sense.
That’s why this is a greenfield opportunity. The companies building context-aware systems now aren’t competing with incumbents—they’re building something incumbents can’t retrofit.
What This Means for You
Here’s where I’m going to be direct, because the stakes are too high for hedging:
If you’re a Founder or CEO:
This is an architecture decision, not a tool decision. You can’t delegate this to your IT team or solve it with a vendor purchase. The companies winning in AI-native GTM are treating this as foundational business transformation—on par with the cloud migration decisions of the previous decade. The most common AI use cases in GTM today are still top-of-funnel: lead generation (61%), campaign and content creation (58%), and meeting transcription (71%). The companies building real advantage are going deeper—embedding AI into process orchestration and institutional memory.
If you’re a Revenue or GTM Leader:
Your playbooks are breaking in real-time. Sales cycles are up 3-4 weeks. Conversion rates are down 5-10 points. Cost per opportunity has nearly doubled for smaller companies. Meanwhile, high AI adopters are achieving 61% quota attainment versus 56% for everyone else—and doing it with leaner teams. You have a choice: lead this transformation or spend the next two years explaining why the gap keeps widening.
If you’re an Operator (RevOps, Enablement, Marketing Ops):
You’re the architects of what comes next. The frameworks you build today will determine whether your organization can adapt or gets disrupted. The good news: there’s never been a more important time for operational excellence. The nervous system architecture requires people who understand data flows, system integration, and process design. That’s you. Post-Sales teams are experiencing the most evolution in the wake of AI—if you can master this transition, you become indispensable.
If you’re in Sales or Customer Success:
The AI isn’t coming for your job—but it is coming to make your job unrecognizable. The best revenue professionals in an AI-native world will be those who can leverage institutional intelligence, collaborate with AI systems, and focus their uniquely human capabilities on relationship building and strategic thinking. Sales- and Channel-sourced opportunities still yield the highest win rates (35-40%)—human relationships matter. But those relationships will be augmented, not replaced.
The Window Is Closing
I wish I could tell you this is a 5-year transition. Something you can study, plan carefully, and implement when the timing feels right.
The data suggests otherwise.
AI spend on internal GTM use cases is expected to increase by 70-80% on average—driven primarily by faster-growing companies and those with more AI-Native products. That means your AI-native competitors aren’t just ahead today; they’re accelerating their investment while you’re still debating where to start.
The compound mathematics are unforgiving. Companies that build integrated learning systems don’t just improve metrics linearly—they improve exponentially. Every customer interaction, every market signal, every internal activity makes their systems smarter. Traditional competitors using the same interactions to drive linear improvements cannot match exponential improvement rates regardless of effort or investment levels.
AI-Native companies—regardless of growth performance—allocate more headcount to Post-Sales teams due to technical onboarding needs and the urge to drive adoption. This has given rise to “forward-deployed engineers” who play a critical role in driving change management, especially in legacy, slower-moving industries.
Companies succeeding share a common pattern: they treat AI implementation as business transformation rather than technology implementation. They invest in data foundations before models. They design for system-wide integration rather than departmental optimization.
And they’re doing it now, while competitors are still debating which chatbot to deploy.
Where to Start
If you’re reading this thinking “okay, but where do I actually begin?”—here’s what I’d suggest:
First, get honest about your current state.
Most companies dramatically overestimate their AI-native readiness. They confuse having AI tools with having AI architecture. Do an honest assessment: Can you identify the patterns in your data that predict success? Does learning from one deal automatically improve every future deal? Does institutional knowledge compound in your organization, or does it walk out the door with every departed employee?
Second, think Memory-first.
The biggest mistake I see is companies starting with the Execution Layer—deploying AI agents to do tasks—without building the foundational layers underneath. Start with Memory. How will you capture and compound institutional knowledge? Everything else builds on that foundation.
Third, pick one workflow to transform completely.
Don’t try to boil the ocean. Pick a single high-value workflow—maybe lead qualification, maybe deal prioritization, maybe churn prediction—and rebuild it as an AI-native nervous system. Build all six layers for that one workflow. Learn what works. Then expand.
Fourth, prepare your organization for the change.
This isn’t just technology transformation. It’s organizational transformation. The skills, roles, and culture that made you successful in the SaaS era won’t automatically translate to the AI-native era. Start building those capabilities now.
What Comes Next
This is the first in a series exploring the Revenue Nervous System framework. Over the coming weeks, I’ll go deep on each layer—the technical architecture, implementation patterns, and real-world case studies of organizations making this transition.
I’ll share what’s working, what’s failing, and what I’m learning from companies on the front lines of this transformation.
But I want to hear from you too. What questions do you have about building AI-native GTM systems? What challenges are you facing in your organization? Where does this framework resonate—and where does it feel disconnected from your reality?
The shift to AI-native GTM isn’t something we can figure out alone. It’s going to take a community of builders, operators, and leaders who are willing to share what they’re learning.
If you’re one of those people, I’d love to hear from you.
Sources
ICONIQ Growth, “2025 State of GTM” (2025)
ICONIQ Growth, “2025 State of Software” (2025)
Foundation Capital, “AI’s Trillion-Dollar Opportunity” (2025)
Gartner, “AI Project Failure Rates and Martech Utilization Research” (2024-2025)
Pattern Engine and Context Layer as separate concepts is a good frame to use.
In case it helps, I'll elaborate on how I'm thinking about these and seeing them in practice (open to feedback, don't have all the answers).
- Examples of the pattern engine: We have an agent that synthesizes product data into hypotheses and natural-language "facts" about usage. The hypotheses power downstream rep actions, while the facts can be used as downstream context (e.g. did the action items we discussed in the last meeting with the customer actually come through in their usage? Or a deal risk agent can pull in usage facts, as right now it only has Gong transcripts and opp data). Similarly, we have agents that research accounts and product facts about them, such as whether they contribute to open-source projects, which can be used for account-based campaigns and rep lists.
- Examples of the context layer: We have agents that craft highly personalized emails, much better than any rep does, getting 10+% reply rates. The agent identifies the persona, use case, and product in order to write. All those are vector stored documents. I'm using a combination of Octave for the email writing and context library, n8n for data pipelines and evals, and customer.io as the MAP/email platform. Octave wants to create a feedback loop where new use cases are dynamically inserted based on opportunity data, i.e. context creating itself, pretty cool!
- I want to build a company-wide GTM context and pattern stores. I'm still learning about how this will come together both technically and strategically, but conceptually here is what will live in those layers. Super open to feedback on what to include and how to build it!
• Data models available to agents in the data warehouse with metadata (model description, dimension definitions).
• Facts / pre-processed data, similar to the first example I shared. Another example: Key contacts in an account, based on transcripts, emails, and opps.
• Tools (MCP servers and custom API functions).
• Something akin to Claude skills, but basically a repo of prompts with metadata on the tools accessible to the skill.
• Deterministic workflows.
Some open questions:
- What architectural patterns are most useful for different use cases? (https://www.anthropic.com/engineering/building-effective-agents) I love how autonomous Cursor is, how do we get there for internal GTM use cases?
- How does observability work for these systems?