
The Engineers You Never Hired
There are two kinds of AI adoption happening right now. Only one of them actually matters.

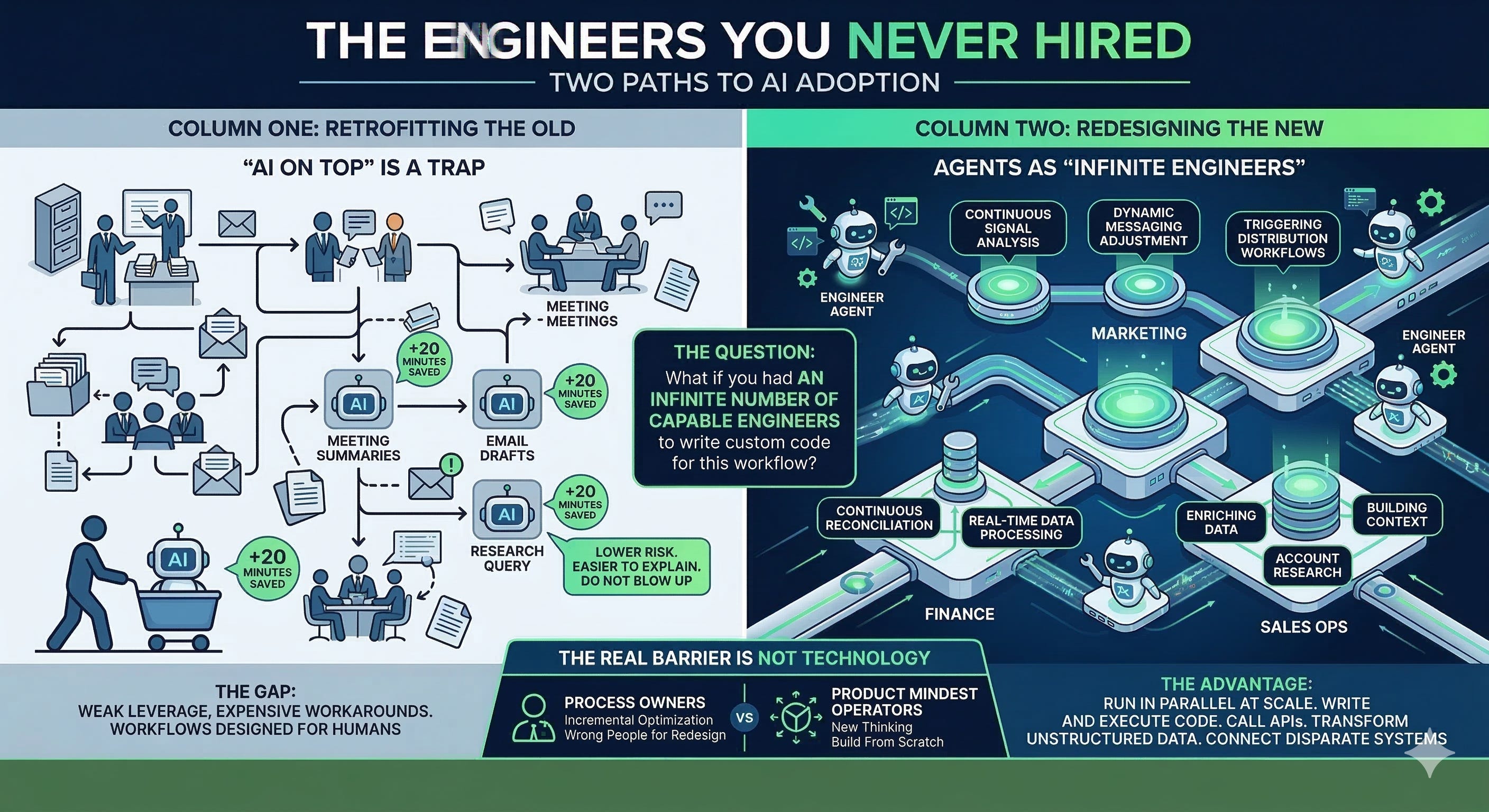
The first kind looks like this: you take an existing process, figure out where you can insert an AI tool, and make it a little faster. Meeting summaries. Email drafts. The occasional research query. You shave 20 minutes here, 30 minutes there. You call it transformation.
The second kind starts from a blank page and asks a completely different question: if we were designing this process today, knowing what AI agents can actually do, how would we build it?
That gap—between retrofitting AI onto old processes versus building new ones with AI at the center—is going to define which companies win the next decade. And most companies are firmly, stubbornly camped in column one.
Why “AI on top” is a trap
There’s a seductive logic to layering AI onto your existing workflows. It’s lower risk. It’s easier to explain to your team. You don’t have to blow anything up.
But it ignores a fundamental problem: most of our workflows weren’t designed with AI’s actual capabilities and constraints in mind. They were designed for humans, augmented by software. That’s a completely different architecture.
AI agents have real limitations. Context windows aren’t infinite. Handoffs between systems are clunky if you don’t think carefully about data flow. If you just drop an agent into a process built for a human, you’re not getting leverage—you’re getting a more expensive workaround.
But AI agents also have capabilities that most processes are completely failing to use. They can run in parallel at a scale that no team can match. They can write and execute code on the fly. They can call APIs, transform unstructured data, and connect disparate systems without waiting on IT to build a custom integration. They don’t get tired at 4 PM on a Friday.
When you layer AI onto an old workflow, you get maybe 20% improvement. When you redesign the workflow from scratch around what AI can actually do, you get something unrecognizable—in a good way.
The “infinite engineers” question
Here’s the mental model that’s been reshaping how I think about this.
When an agent can write code and interact with any API, it’s not just an automation tool. It’s effectively an expert engineer you can deploy against any business problem, at will, without a headcount request or a six-month hiring process.
So the question I’ve started asking about any process is this: what would you do differently if you had an infinite number of capable engineers who could write software specifically for this workflow?
Not a generic software platform. Not an off-the-shelf tool. Engineers who would actually sit down, understand your process end-to-end, and write custom code to solve your specific version of the problem.
What if those engineers connected your disparate data sources so every part of the process had the full context it needed? What if they wrote automation for every repeated task, no matter how small? What if they built custom integrations between your systems that no vendor was ever going to prioritize? What if they could comb through thousands of rows of unstructured data and surface exactly what each step of your workflow actually needed?
When I ask that question, most processes look completely different.
This isn’t theoretical
I’ve seen it get real in places you wouldn’t expect.
In marketing, we’re used to thinking about content production as a human-driven workflow with AI writing assistance sprinkled in. But if you redesign from scratch—treating agents as the engineering backbone—you’re not producing content faster. You’re running continuous audience signal analysis, dynamically adjusting messaging, and triggering distribution workflows based on engagement patterns, all in parallel, all automatically. That’s a different function.
In finance, the traditional close process involves a lot of humans moving data between systems, reconciling exceptions, and waiting on approvals. An agent that can write code and hit APIs doesn’t need most of that scaffolding. It becomes something closer to continuous reconciliation—not a monthly sprint.
In sales operations, think about how much time goes into enriching data, researching accounts, and building the context a rep needs before a conversation. Most of that is repeated, structured work that a capable engineer would have automated three years ago if anyone had asked. Agents can do it now, at scale, for every account, every time.
Not every process has this upside—I want to be clear about that. Some workflows are genuinely human judgment-intensive in ways that don’t yield to this kind of redesign. But there are far more that aren’t than most leaders realize.
The real barrier isn’t technology
Here’s what I keep running into: the companies that are stuck in column one aren’t stuck because the technology isn’t ready. They’re stuck because they’re asking the wrong people to redesign the workflows.
Process owners—the people who know how workflows actually run—are often the last people to imagine what those workflows could look like if built from scratch. They’re too close to it. They optimize incrementally. That’s not a criticism; it’s how expertise works.
The redesign question requires a different kind of thinking. It requires someone who can look at a process and ask: “If I weren’t constrained by how we’ve always done this, and I had access to agents that could write and run code, what would I actually build?”
That’s a product mindset applied to operations. And most organizations don’t have many people operating that way.
The teams that figure it out—that start treating AI agents as their unlimited engineering capacity—will run circles around the ones still optimizing their old playbooks. Not because they have better AI access. Everyone has access.
Because they asked a better question first.