
How to Ship Your First GTM Agent in 30 Days
The 30-day sequence to ship your first running GTM agent

Most companies do not have an AI strategy problem. They have a first-agent problem. They have a slide that says “agentic GTM” and a budget line that says “AI tooling” and nothing in production that a single person on the revenue team actually depends on. The strategy is fine. The deck is fine. What is missing is one agent, running, doing real work, that nobody wants to turn off.
I watch this happen constantly. A leadership team spends a quarter mapping a transformation roadmap with eleven workstreams, and at the end of the quarter the number of GTM agents actually running in their business is zero. Not because the team is incapable. Because nobody picked one workflow, drew a box around it, and shipped it. The roadmap was the procrastination. The first agent is the work.
Here is the thing about the first agent. It is the hardest one you will ever build, and it has almost nothing to do with the technology. The model is good enough. The tools are good enough. What is hard is the organizational act of choosing one workflow, defining what “good” means precisely enough to measure it, running it next to a human without flinching, and then killing the manual process when it works. The second agent is ten times easier because by then the company has done the hard part once. It has proof. It has a pattern. It has a person who has shipped.
So this playbook is about the first one. Thirty days. One workflow. End to end. Running.
And it is written for the Tactical CEO, which means I want to be precise about your job, because your job is not the one you think it is. You are not building the agent. If you are the CEO and you are in the prompt, something has gone wrong. Your job is to install the conditions under which the agent gets built and survives. You name the owner. You protect the thirty days. You set the cancellation target. You demand the exit criterion. Four moves, and if you make them, the agent ships. If you skip them, you get another roadmap.
Three readers should be following along here, and the job splits cleanly. The individual operator builds the thing. The leader clears the runway. The founder or CEO sets the target and refuses to let the calendar eat it. I will mark who does what as we go.
Here is the sequence.

Days 1-3: Pick the Workflow
Everything downstream is determined by this choice, and most teams get it wrong by picking the workflow that is most exciting instead of the one that is most shippable. The first agent is not where you prove ambition. It is where you prove the company can ship at all.
The move. Map your GTM workflows. Not your org chart. Your workflows. The repeated, nameable units of work that move revenue: lead research, inbound triage, meeting prep, CRM hygiene, follow-up drafting, renewal flagging, deal-desk approvals, onboarding sequences. Then score each one on three axes. Frequency: how many times a week does this run? Manual hours: how much human time does each run burn? Clarity: how cleanly can you describe what “good output” looks like? Multiply, sort, and the top of the list is your candidate. High frequency times high manual-hours times high clarity. Pick ONE.
The clarity axis is the one people undervalue. A workflow that runs two hundred times a week but where “good” is fuzzy and contested will sink your first agent in edge cases. A workflow that runs forty times a week but where good is obvious to everyone is a far better first target. You want frequency for ROI and clarity for shippability. Where they overlap is your agent.
What good looks like. One workflow named on a whiteboard, with a number next to it. “Inbound lead research. Runs roughly sixty times a week. Eats about twenty minutes of an SDR’s time each run. Good output is a five-field brief: company, funding, role fit, recent trigger, and a suggested opener.” That sentence is the deliverable for days 1 through 3. If you cannot write that sentence, you have not picked yet.
The CEO’s role here. You name the owner. This is the single most important thing you do in the entire thirty days, and it takes one decision. One person owns this agent end to end. Call them the Agent Builder. Not a committee. Not “the RevOps team.” A name. The Agent Builder can be a RevOps analyst, a sharp SDR, a sales engineer, anyone close to the work with enough technical comfort to wire tools together. What matters is that the responsibility lands on a person, because agents that belong to everyone get built by no one. If you do nothing else as CEO, do this.
Common mistake. Picking the flashiest workflow instead of the most shippable one. The autonomous outbound agent that personalizes at scale is the dream, and it is a terrible first agent because “good” is contested, the blast radius is your brand, and one bad send is a customer-facing incident. Start somewhere internal, high-frequency, and low-blast-radius. Earn the right to the flashy one by shipping the boring one.
Exit criterion. One workflow is named, scored against the other candidates, and written as a single sentence with a frequency number and a manual-hours number attached. The Agent Builder is named. When that is true, days 1 through 3 are done.
Days 4-7: Define the Contract
This is where most first agents die quietly, before a line of anything gets built. The team skips straight to building because building feels like progress, and they never wrote down what the agent is actually supposed to produce or how they would know if it worked. Then four weeks later there is a thing that runs and no way to say whether it is any good. Define the contract first.
The move. Write the agent’s contract on one page. Four parts.
Inputs: exactly what the agent receives. The lead’s email and company domain. The inbound form submission. The CRM record. Be specific about what is and is not available at runtime, because half of agent failures are the agent reaching for context it was never given.
Outputs: exactly what the agent produces, in what format, to what destination. “A five-field brief written to a Slack channel and appended to the CRM contact record.” Not “research on the lead.” A format a human can check at a glance.
What good looks like: the quality bar, written as something you can actually evaluate. Pull five real past examples that a human did well. Those are your gold standard. The agent’s output gets compared against them.
How you measure it: the metric, against the human baseline. Time saved per run. Accuracy versus the human-done version. Acceptance rate, meaning how often a human ships the agent’s output without rewriting it. Pick the one or two that matter and write down the current human number, because you cannot prove the agent is better than the human if you never measured the human.
What good looks like. A one-page contract that a person who has never seen the workflow could read and then correctly judge whether a given agent output passed or failed. If two people read the contract and disagree about whether an output is good, the contract is not done. Tighten it until they agree.
The CEO’s role here. You demand the exit criterion before a single thing gets built. The Agent Builder brings you the contract, and the question you ask is one sentence: “What number tells us this worked, and what is that number for a human today?” If they cannot answer, the agent is not ready to be built, it is ready to be re-scoped. This is a five-minute conversation and it is the highest-leverage five minutes in the project. You are not reviewing the work. You are refusing to let the work proceed without a definition of done.
Common mistake. No human baseline. The team builds the agent, it produces plausible output, everyone nods, and nobody can say whether it is faster or more accurate than what the SDR was already doing. Without the baseline you have a demo, not a result. Measure the human first, even roughly. A baseline that is approximate beats a baseline that does not exist.
Exit criterion. A one-page contract exists with inputs, outputs, a gold-standard set of five examples, and a named metric with the current human number written next to it. When that is true, days 4 through 7 are done.
The Architecture Every Agent Gets Built Against
The one-page contract is the spine. It is not the whole skeleton. The contract names what goes in, what comes out, what good looks like, and how you measure it, which is a real start, but a contract is not yet an agent. This is where most first agents quietly turn into demos. The team has a contract, they hand it to a model, the model produces something plausible, and nobody can say why it works on Monday and falls apart on Thursday. The reason is almost always a missing layer.
So here is the architecture I build every agent against. Seven layers, plus three things most people leave out, plus one rule that matters more than all of it. Your contract from days 4 through 7 already covers four of these layers. The other three are what separate an agent you can cut over to from a science project you keep babysitting.
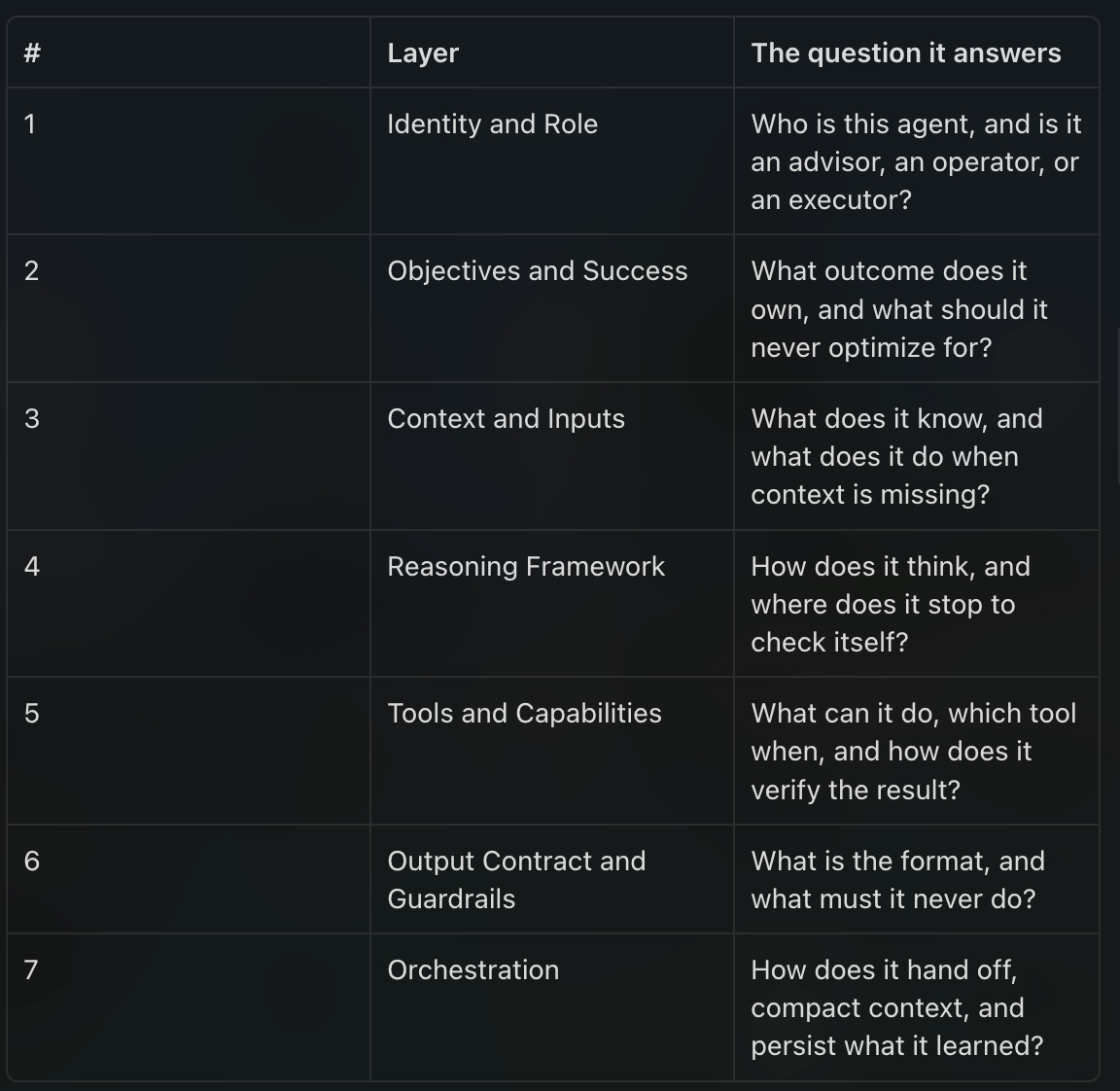
Layer 1, identity. Name the agent, its domain, and one thing that decides everything downstream: its authority level. Advisor recommends and a human acts. Operator acts but asks permission for anything with real blast radius. Executor acts on its own inside declared bounds. Your first agent should almost always be an advisor or a tightly scoped operator, because authority is where damage lives. And write the “you do NOT” list. Name the specific ways this agent goes wrong, not generic negatives. “Never fabricate a trigger event it cannot source from the input” teaches the model something. “Be helpful” teaches it nothing.
Layer 2, objectives. The outcome it owns, and the anti-goal. The anti-goal is the part people skip and it is the part that saves you. “Optimize for accuracy even if it means flagging the lead as out of scope instead of guessing” is an anti-goal. It tells the agent what to sacrifice when the two things it wants are in conflict, which is exactly the moment unguarded agents improvise.
Layer 3, context. What is in scope, what is out, and the single most undervalued instruction in agent building: what to do when context is missing. An agent that guesses when it lacks input is an agent that hallucinates on a schedule. The fix is one line: when a required input is missing, do not guess, say what is missing and stop.
Layer 4, reasoning. Here is the counterintuitive part. If you are building on a modern thinking-capable model, do not script its thought process. Telling a reasoning model to follow your five steps usually makes it worse, because it plans better than your script does. Constrain the output, not the thinking. The one piece worth keeping is a verification step: before it answers, have it check its own work against the contract, and when something is ambiguous, ask one clarifying question instead of charging ahead.
Layer 5, tools. What the agent can reach, when to pick one tool over another, and the step nearly everyone omits: post-tool verification. After the agent calls a tool, it has to check that the result is actually what it asked for before it acts on it. Skip this and one bad lookup cascades into a confidently wrong output. This is the single most common hole in a first agent. If you do nothing else technical, make the agent verify its tool results before it trusts them.
Layer 6, output and guardrails. The format, and the hard nevers. Use blast-radius gates: read-only actions can run on their own, anything that writes asks for confirmation, anything customer-facing or irreversible requires a human. That gate, tied to the authority level from Layer 1, is what makes an agent safe to cut over to in week 4.
Layer 7, orchestration. Mostly skip this for agent number one, and that is the point of naming it. Orchestration is how an agent delegates to other agents, compacts a long conversation, and persists what it learned between runs. Your first agent does one thing, so it barely needs this. But know it exists, because agent number five will, and the most common orchestration failure is a fuzzy delegation map. “Hand off to a specialist when needed” is not a map, it is a shrug. When you get there, name exactly who receives what.
Then three things that are not optional, even though everyone treats them as extras.
A role contract, if the agent owns an outcome. For anything modeled on an actual revenue role, write what outcome it is accountable for, what artifacts it emits, what it consumes upstream, what consumes it downstream, and the metrics that prove it works. This is the Signal to Decision to Action to Feedback loop made concrete, and it is what keeps a GTM agent from drifting into a generic chatbot.
Examples. Two to five, every time. Show the agent a standard success, an ambiguous edge case it should ask about, and a bad input it should refuse. On a strong model, two or three real examples shape behavior more than any amount of instruction prose. The five gold-standard examples from your contract are the start of this. Add an edge case and a failure case and you are done.
Observability. Have the agent emit a small structured record every time it runs: what it received, what it did, whether it escalated, and the outcome. Ungoverned agents become ungovernable the moment you have more than a couple. A logging stub on agent one is a habit that pays off at agent ten.
And the rule that matters more than the rest: keep the whole spec tight. There is real research, and my own repeated experience, behind a density ceiling of roughly a hundred and fifty lines. Past that, agents get worse, not better, because the model’s attention degrades across a bloated spec and the redundant lines cost you both accuracy and money. Density beats comprehensiveness. Anything that is a standard process, a template, or a rubric does not belong in the agent itself. It belongs in a skill the agent loads only when it needs it. The agent spec holds identity, judgment, and the things the model cannot figure out on its own. Everything else loads on demand.
That is the difference between a tool and a system, which is the whole game. A tool is a clever prompt that works until it doesn’t. A system is an agent with an identity, a verified set of capabilities, guardrails proportional to what it can break, examples of right and wrong, and a record of every run. The first one takes a few extra hours to build this way. Every one after it inherits the pattern.
For agent number one, you genuinely need only Layers 1, 2, 3, and 6, plus a couple of examples and a verification step. That is the minimum viable agent. Build that, ship it, and add the rest as the workflow earns it. The architecture is the standard you grow into, not a gate you have to clear before you start.
Week 2, Days 8-14: Build the First Version
Now you build, and the entire discipline of week 2 is one word: thin. One workflow, end to end, running, even if it is ugly. The failure mode of week 2 is not building a bad agent. It is building half of an ambitious agent. A thin slice that works beats a thick slice that almost works, every single time.
The move. Build the narrowest version of the agent that takes the real input, does the real work, and produces the real output to the real destination. End to end. If the contract says “lead email in, five-field brief to Slack out,” then by the end of week 2 a real lead email goes in and a real brief lands in Slack. It does not have to handle every edge case. It does not have to be elegant. It has to be whole. One complete path from input to output, running on real data, even if it only handles the clean cases for now.
Resist the urge to build the pretty version. No dashboard. No configuration UI. No handling of the seventeen rare input formats. The clean path, working, on real inputs. The edge cases are week 3’s job, and trying to handle them now is how week 2 turns into week 6.
What good looks like. You can point at it and say “watch this,” paste in a real lead, and a real brief appears in the real Slack channel. It is ugly. It misses some cases. It works. That is the bar. A running thin slice on day 14 is worth more than a beautiful architecture diagram of the full system.
The CEO’s role here. You protect the thirty days. Week 2 is when the organization’s gravity tries to pull the Agent Builder back onto their old job. A fire breaks out, a board ask lands, a customer escalates, and the easiest thing in the world is to grab the most capable person, who is your Agent Builder, and put them on it. Do not. The whole premise of a thirty-day sprint is thirty protected days. If the Agent Builder gets pulled for a week, you do not have a thirty-day agent, you have a sixty-day maybe. Your job is to be the wall between the Agent Builder and the next fire. Leaders, this is yours too: clear their calendar, reassign their tickets, and make it socially expensive for anyone to interrupt the build.
Common mistake. Building wide instead of deep. The team tries to make the agent handle every input variation and every output format in week 2, gets buried in edge cases, and arrives at day 14 with a sophisticated half-thing that has never once run end to end. Ship the clean path first. The agent that runs on Monday teaches you more than the agent that is still being designed on Friday.
Exit criterion. A real input produces a real output to the real destination, on real data, end to end, at least once. When you can demo that live, week 2 is done.
Week 3, Days 15-21: Run It in Shadow Mode
The agent works on the clean path. Now you find out what the clean path was hiding. Week 3 is shadow mode: the agent runs next to the human, on the same real inputs, at the same time, and nobody ships the agent’s output to anyone yet. You compare. You measure. You fix the edge cases the real world surfaces.
The move. Run the agent in parallel with the human on live work. Same leads, same tickets, same inputs, both producing output. The human’s output is what actually gets used this week. The agent’s output gets logged and compared against it and against the contract’s gold standard. Every divergence is a finding. The human caught a trigger event the agent missed. The agent produced a cleaner opener than the human. The agent choked on a lead with no company domain. Each one is either a bug to fix or a boundary to document.
This is also where you measure the contract metric for real. Time per run, agent versus human. Acceptance rate: if a human had shipped the agent’s output, how often would it have been fine as-is? You are building the evidence that the agent is at or above the human baseline, on real work, before you let it touch anything live.
What good looks like. A week of side-by-side logs. The agent matches or beats the human on the named metric across the clean cases, and the edge cases where it fails are documented and either fixed or explicitly ruled out of scope. You know precisely where the agent is trustworthy and where it is not, because you watched it run against a human for a week instead of guessing.
The CEO’s role here. You hold the line on the cancellation target you are about to set, and you ask one question at the week-3 readout: “Is it at or above the human baseline yet?” Not “is it perfect.” At or above the human. Humans miss things too. The bar for cutover is not flawlessness, it is “as good as or better than the person doing it today, on the cases we have scoped.” If you let the team chase perfection here, the agent never ships, because nothing is perfect and shadow mode can run forever. Your job is to define “good enough to cut over” as “beats the human on the metric we agreed to,” and then push for the cutover.
Common mistake. Letting shadow mode become permanent. Shadow mode is comfortable. The agent runs, nobody depends on it, there is no risk, and the team can tweak forever. That is not safety, it is avoidance. Shadow mode has a one-week clock. At the end of the week you make a call: cut over, or kill the project and pick a different workflow. What you do not do is run a fourth week of shadow mode because someone is nervous.
Exit criterion. A week of side-by-side data shows the agent at or above the human baseline on the contract metric, with edge cases documented and either fixed or scoped out. The cutover decision is made. When that is true, week 3 is done.
Week 4, Days 22-30: Cut Over and Kill the Manual Process
This is the week that separates a real agent from a science project, and it is the week most companies never reach, because cutting over means committing. Shadow mode is reversible. Cutover is a decision. You are saying: from now on, the agent does this, and the human stops doing it the old way. The agent is no longer running next to the process. The agent is the process.
The move. Four things, in order.
Cut over. The agent’s output now goes live. The human moves from “doing the work” to “supervising the agent,” which mostly means spot-checking and handling the documented edge cases the agent does not cover. The default is the agent. The exception is the human.
Kill the manual process. Actually kill it. Not pause, not “keep it as a backup just in case.” The manual workflow comes off the team’s plate. If the SDR is still doing lead research by hand “to be safe,” you have two processes and zero leverage, and the agent will quietly atrophy because nobody depends on it. Make the agent the only path.
Hit the cancellation target. Here is where the CEO’s number comes due. If this workflow was being done with a SaaS tool you were paying for, cancel it or earmark it for cancellation at renewal. If it was being done with human hours, those hours are now reclaimed and explicitly redeployed to higher-value work, named, not vaguely “freed up.” The first agent should retire something. A subscription, a contractor line, a chunk of hours. That retirement is the proof the agent is real, and it funds the next one.
Write the runbook and pick agent #2. A one-page runbook: what the agent does, where it runs, how to tell if it is broken, who owns it, what to do when it fails. Then, on day 30, the Agent Builder names the next workflow off the day-1 scoring list. The pattern is now installed. Agent #2 will take half the time.
What good looks like. The manual process is gone. The agent runs in production and a real person depends on its output every day. A line item got cancelled or a block of hours got formally redeployed. There is a runbook. There is a named candidate for agent #2. The company has shipped one, and more importantly, it now knows how.
The CEO’s role here. You set the cancellation target at the start of the month, and in week 4 you collect it. “This agent retires the X subscription,” or “this agent gives the SDR team back ten hours a week that go to live conversations.” You name that target on day 1 and you hold the team to it on day 30. Without a cancellation target, the agent becomes additive: a new thing on top of all the old things, and additive AI is how companies end up paying more and moving the same. The cancellation target is what makes the agent a replacement instead of an addition. That is your number to set and your number to enforce.
Common mistake. Running the agent and the manual process in parallel forever because cutting the manual process feels risky. This is the most common failure in the entire thirty days, and it is fatal in slow motion. Two parallel processes means the agent never becomes load-bearing, nobody truly depends on it, the cancellation target never gets hit, and within a quarter the agent is a curiosity nobody maintains. The cutover is the point. If you are not willing to kill the manual process, you were never serious about the agent.
Exit criterion. The agent runs in production, the manual process is dead, the cancellation target is hit or scheduled, the runbook exists, and agent #2 is named. When all five are true, you have shipped your first GTM agent in thirty days.
Why the First One Is the Hardest, and the Most Important
The first agent costs you a month and teaches you everything. It forces the company to learn the one skill that the entire AI-native transition actually depends on, which is not prompting and is not tooling. It is the organizational muscle to scope one workflow, define done, measure against a human, cut over, and kill the thing it replaced. That muscle is the whole game. Companies that have it ship agent after agent. Companies that do not have it accumulate roadmaps.
Once the muscle exists, the constraint stops being capability and becomes throughput. You will not be asking “can we build an agent?” You will be asking “which workflow next, and who owns it?” That is a completely different company than the one that started the month with a deck and a budget line and nothing running. The first agent does not just automate a workflow. It converts the organization from talking about agents to shipping them. That conversion is worth far more than the twenty minutes a week the agent saves.
The individual operator gets a shipped artifact and a new identity: the person who builds the agents. The leader gets a repeatable thirty-day pattern to run again and again across the revenue org. The CEO gets the only thing that actually matters at the top, which is proof that the company can install AI into its operating model and retire what it replaces, instead of layering AI on top and paying twice.
The window for this is not open forever. The companies building this muscle now are compounding it while everyone else is still mapping. Eighteen months from now the gap between the company that shipped its first agent this quarter and the company that is still planning its transformation will not be a quarter. It will be the difference between an organization that runs on agents and one that runs slides about them.
Pick the workflow. Name the owner. Protect the thirty days. Ship the first one.
Below the line: the build prompt I would hand the Agent Builder on day 1, the SaaS-spend-to-agent mapping worksheet for finding your cancellation targets, and the companion interactive guide that walks the full thirty-day sequence with the templates built in.
Free preview ends here. Everything above is the full 30-day sequence, free to read and free to run: the week-by-week moves, the exit criteria, the CEO’s role at each phase. Below, for paid subscribers, are the copy-paste assets that make it faster: the first-agent build prompt, the SaaS-spend-to-agent mapping worksheet, and the companion interactive guide.
