
2/4/26: How to Replace a $300K Competitive Intel Team with $30 and 4 Hours

Welcome BACK to the 2026 GTM AI Podcast
Just as a reminder, we have CHANGED FORMATS, which we are really excited about, where we have practitioners and GTM leaders/professionals showing off workflows that they are using right now to help you know what is working.
Make sure that you participate in the quick 5-10 min AI Led survey for the GTM AI 2026 report, will be sharing all the research in a couple weeks when we have enough respondents.
Now lets dig in, who would have thought how much intel podcasts that your competition either hosts or been on has in store for you? Lets dig in.

You can go to Youtube, Apple, Spotify as well as a whole other host of locations to hear the podcast or see the video interview.
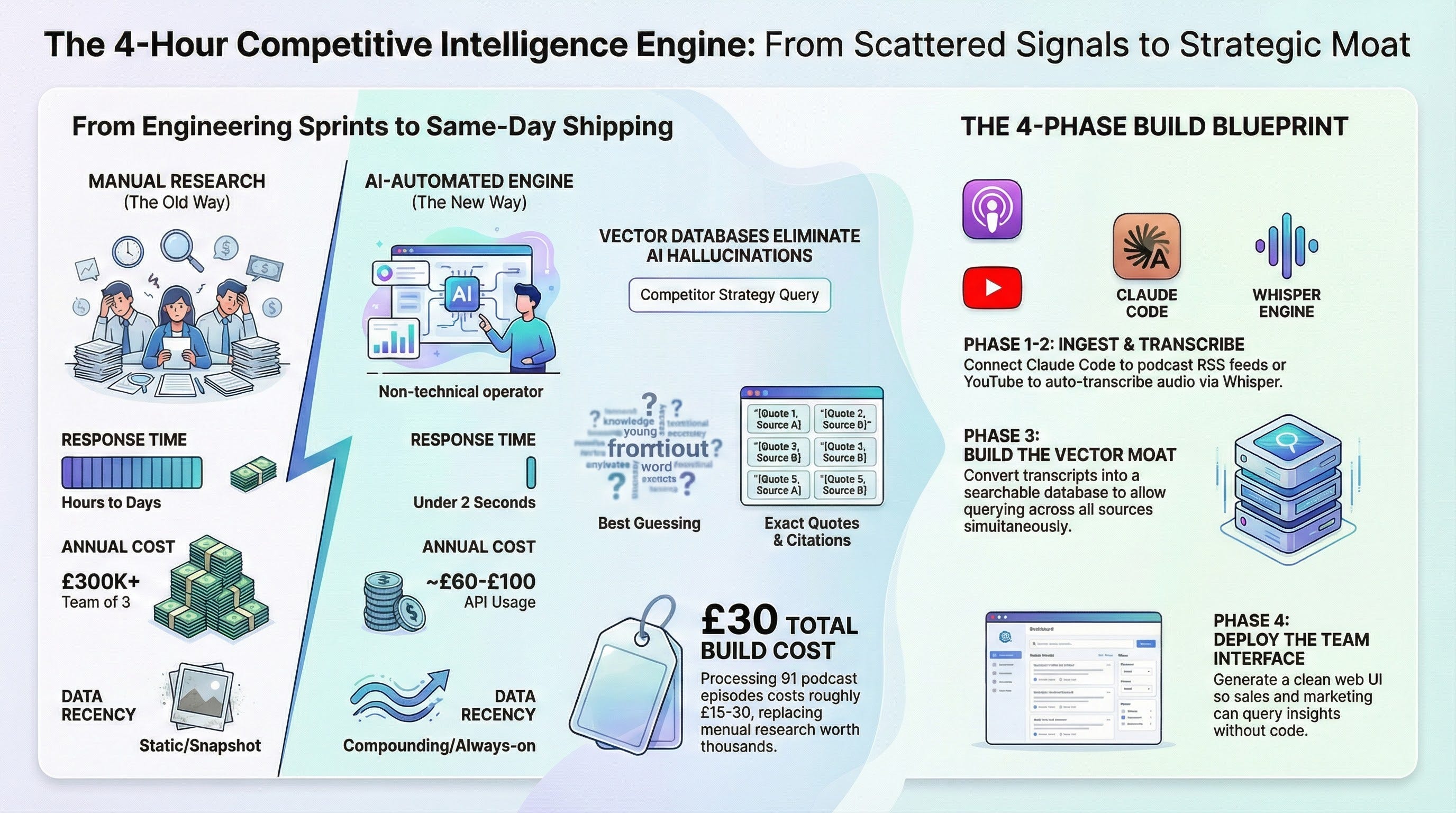
Most competitive intel sits on shelves collecting dust while your competitors ship faster.
Your team spends weeks building battle cards. By the time they reach your reps, your competitor has shifted messaging. You find out three deals later when someone mentions it in a loss review. Your head of sales asks why competitive enablement is always behind. You don’t have a good answer.
Scott Ewalt just demonstrated building a competitive intelligence engine from scratch in 4 hours. Zero Python experience. No developer hire. Just Claude Code and a clear outcome: turn scattered competitive signals into queryable intelligence.
The result: 91 podcast episodes transcribed, where he uses our own podcast as the source, stored in a vector database, with a custom web UI that surfaces strategic insights competitors broadcast publicly but you’ve never synthesized.
PART 1: What Scott Built & Why It Matters
Episode Summary
Guest: Scott Ewalt - Former product, marketing, and CX operator who’s spent his career finding “unfair advantages” through technology. Not a developer. Never wrote production code. Didn’t open a terminal before Q4 2025.
The Demo: Building a competitive intelligence system that:
Transcribes and stores 91 podcast episodes (81.2 hours of content)
Creates a queryable vector database with zero hallucinations
Builds a custom web interface for team queries
Returns specific quotes with episode citations and timestamps
Build Time: 4 hours total
Cost: £15-30 in API usage
Tools Used:
Claude Code (free agentic coding assistant)
Cursor (code editor, free tier)
OpenAI API (Whisper for transcription)
Anthropic API (for embeddings and queries)
Python scripts (auto-generated by Claude Code)
The Strategic Insight: Your competitors are broadcasting their entire strategy on podcasts, investor calls, conferences, and media appearances. That signal sits scattered across the internet. The competitive advantage goes to whoever consolidates it first.
Scott demonstrated that non-technical operators can now build systems that previously required engineering teams. The bottleneck just evaporated.
Strategic Impact: Why This Changes GTM Intelligence
1. Competitive intelligence is everywhere, but aggregated intelligence creates unfair advantage
The pattern most teams miss: You’re doing point-in-time competitive research. Someone asks “what’s our competitor saying about AI?” and you Google it, find a recent article, update a slide. That’s snapshot intelligence. It goes stale the moment you capture it.
What Scott built: Infrastructure that compounds. The system he demonstrated analyzes the GTM AI Academy podcast, but the architecture works for any audio content:
Competitor CEO interviews
Industry expert panels
Customer testimonials on YouTube
Earnings calls
Conference presentations
The strategic shift: What used to require a competitive intelligence team (3-5 people, £300K+ annually, constant manual updates) now runs as an automated system. Your ops team can build this same-day.
Real-world application for GTM teams:
Your RevOps person (who maintains your CRM and builds Salesforce reports) can build this today. They don’t need to learn Python. They don’t need to understand APIs. They describe the outcome. Claude Code handles implementation.
Example sources to consolidate:
Every podcast your top 3 competitors appeared on in the last 12 months
All earnings calls for public competitors
YouTube conference talks from their leadership team
Customer review sites (G2, Capterra, TrustRadius)
Your own sales call transcripts from Gong or Chorus
Query the system: “How is [Competitor] positioning their AI capabilities in enterprise deals?”
Get back: Specific quotes from their CEO’s podcast interview last month, their Q3 earnings call, customer testimonials on G2, and your rep’s call notes from competitive deals. All synthesized with source citations.
The capability gap opening: Teams that realize their ops people can build these systems will move 5x faster than teams waiting for vendors to productize this. You have maybe 6-12 months before this becomes table stakes.
2. Vector databases eliminate the hallucination problem in competitive research
The challenge Scott hit: Once he had 91 transcribed episodes sitting in markdown files, he tried the obvious thing. Dropped the folder into Claude, asked it to analyze. Got back high-level summaries like “AI can improve sales productivity” and “teams struggle with adoption.”
Generic. Vague. Useless for battle cards.
The solution: Build a vector database. This lets you query your competitive intelligence and get exact quotes with source citations instead of AI “best guessing” answers.
When Scott asked his system “What are some of the top use cases for AI in sales?”, it didn’t give him generic summaries. It returned:
Specific insight: “Only 39% average quota attainment across sales teams”
Source: Episode 23, timestamp 14:32
Context: Discussion about why AI alone doesn’t fix broken sales processes
Before:
“AI improves sales productivity” (generic, can’t use this)
After:
“Sales teams using AI for call prep see 34% productivity gains, but only top performers. Bottom quartile reps improve 8%. The difference: top performers redesign their workflow around AI.” (Specific, actionable, backed by source)
The tactical advantage for your battle cards:
Your competitive positioning isn’t based on “we think they’re saying X.” It’s based on “in their Q4 investor call, they explicitly stated X.” Your reps can reference exact claims. Your battle cards cite specific competitor statements with source attribution.
No more “I think they said...” in deal reviews.
3. Non-technical operators can now build what required engineering sprints
Scott’s background: Not a developer. Never opened a terminal before Q4 2025. Has led product, marketing, and customer experience teams as an operator focused on driving customer value.
What he built in 4 hours:
Automated podcast ingestion system (finds RSS feeds, downloads audio)
Transcription pipeline (processes 81+ hours of audio through Whisper API)
Vector database with embeddings (stores content for precise querying)
Custom web interface (clean UI for asking questions and viewing results)
Multi-source synthesis capabilities (ready to add more competitive intel)
The old world (pre-Claude Code):
This would hit your engineering backlog. You’d write a Jira ticket: “Build competitive intelligence database.” Engineering would estimate 2-3 sprints. It would get prioritized against revenue-generating features. It would probably never ship.
The new world:
Your RevOps or Marketing Ops person spends 4 hours with Claude Code. Ships it same-day. Adds it to the team’s workflow by end-of-week.
How Scott describes the “debugging” process:
“My version of debugging is hitting yes. It’s ridiculous. ‘Hey, I’m gonna fix this for you. Do you want me to do this?’ Yeah, go ahead. That part would just take some time. It would run into a wall and then it would come back and need my help.”
That’s it. That’s the entire debugging process. No Stack Overflow searches. No reading documentation for libraries you’ve never heard of. Claude Code identifies the issue, proposes a fix, asks permission, implements it.
What this means for GTM organizations:
Your RevOps team just became builders. Your Marketing Ops team can ship tools. The “we need engineering resources” bottleneck evaporated.
That dashboard your sales team has been asking for? Your ops person can build it this week. That custom integration between your CRM and your product usage data? Build it. That automated competitive intelligence system? Build it.
4. The system compounds: build once, query infinitely, automate updates
The short-term value: Scott can now query 91 podcast episodes instantly. “What messaging is resonating?” “What objections are prospects raising?” “How are competitors positioning against legacy solutions?”
He gets answers with exact quotes and episode citations in seconds. Instead of listening to 81 hours of content.
The long-term advantage: This isn’t a one-time analysis. It’s infrastructure that compounds.
How the system scales:
Start with podcasts (like Scott did). Then add:
Competitor earnings calls (transcribe from investor relations pages)
Conference presentations (YouTube talks from competitor leadership)
Customer review sites (G2, Capterra, TrustRadius testimonials)
Your own sales call transcripts (what objections are reps actually hearing?)
Industry analyst reports (Gartner, Forrester content on your category)
LinkedIn posts from competitor executives (what themes are they pushing?)
All of it feeds the same vector database. You query across all sources simultaneously.
The automation layer Scott mentioned:
You can set this to run automatically. New podcast episode published? The system detects it, transcribes it, adds it to the database. Zero manual work.
Competitor releases earnings call? Automated ingestion, transcription, database update.
Your competitive intelligence becomes always-on. Battle cards update automatically when new competitive signals emerge. Your messaging adapts to market shifts in real-time, not quarterly.
The competitive moat this creates:
Teams doing manual competitive research fall further behind every week. They’re doing snapshot intelligence. You’re running a compounding system.
Six months from now, you have 300+ sources in your database. They have a deck someone updated last quarter. Your reps have answers to competitive questions in real-time. Their reps are guessing. The gap widens until it becomes insurmountable.
Use Cases: What GTM Teams Can Build This Week
1. Competitive Messaging Tracker
Monitor all podcasts featuring your top 3 competitors
Track how their positioning evolves over time
Alert when they shift messaging on key capabilities
Query: “How has [Competitor] changed their AI messaging in the last 6 months?”
2. Buyer Intelligence System
Aggregate customer reviews from G2, Capterra, TrustRadius
Synthesize what buyers actually care about (not what you think they care about)
Identify gaps between competitor claims and customer reality
Query: “What pain points are buyers citing that competitors aren’t addressing?”
3. Sales Objection Database
Feed your own Gong/Chorus call transcripts into the system
Surface common objections across all deals
Cross-reference with competitor messaging
Query: “What objections about pricing are reps hearing in enterprise deals?”
4. Industry Trend Validator
Consolidate analyst reports, conference talks, expert podcasts
Identify which “trends” are real vs. hype
Track how expert consensus evolves
Query: “Are industry experts actually recommending AI-native solutions or is it mostly vendor push?”
5. Partner/Ecosystem Intelligence
Transcribe partner webinars and ecosystem events
Track which integrations are getting traction
Identify partnership opportunities before competitors
Query: “Which CRM integrations are partners most excited about?”
PART 2: How to Build Your Own Competitive Intel Engine
This is the complete step-by-step walkthrough to replicate Scott’s system. Each phase includes exact prompts, expected timelines, what success looks like, and common pitfalls.

Phase 1: Setup (15 minutes)
What You Need
Tools to download:
Claude Code (free, download from claude.ai/code)
Cursor (optional but helpful for viewing files, cursor.sh - free tier available)
API keys to create:
OpenAI API key (for Whisper transcription, pay-as-you-go)
Anthropic API key (for embeddings and queries, pay-as-you-go)
Cost reality: Processing 91 podcast episodes (81+ hours of audio) cost Scott approximately £15-30 total. This isn’t enterprise budget territory. This is “expense it” money.
Installation Steps
Download Claude Code - Go to claude.ai/code, download for your operating system, install and open
Get OpenAI API Key - Go to platform.openai.com → API keys → “Create new secret key”
Get Anthropic API Key - Go to console.anthropic.com → API keys → “Create key”
Create Your Project Folder - Open Claude Code, create a new project folder (name it “competitive_intel”)
Important: Claude Code runs locally on your machine. Your transcripts, your database, your files all stay on your computer. Nothing uploads to a third-party service unless you explicitly configure that.
What Success Looks Like: You have Claude Code open with an empty project folder and both API keys saved somewhere you can access them.

Phase 2: Transcribe Your First Competitive Source (30-90 minutes)
The Exact Prompt to Use
Open Claude Code and enter this prompt (replace the bracketed sections):
I want to build a competitive intelligence system. Start by pulling all episodes from [PODCAST NAME - example: "The GTM AI Academy Podcast"].
Find the RSS feed, download the audio files, and transcribe them using OpenAI's Whisper API. Save each transcript as a markdown file in a clean folder structure with episode names and numbers.
Here's my OpenAI API key: [YOUR API KEY]What Claude Code Will Do
Search for the podcast RSS feed - It will find the feed URL automatically
Parse the feed to get all episode URLs - Lists all episodes available
Download audio files - Downloads each episode’s audio file
Call Whisper API for transcription - Transcribes speech to text (most time spent here)
Create folder structure - Makes a folder:
podcast_transcripts/[PODCAST_NAME]/Save each transcript as markdown - Files named like:
Episode_01_Guest_Name.mdProvide a summary - Shows you what it transcribed, total episodes, any errors
Expected Timeline
For 10-20 episodes: 20-40 minutes
For 50+ episodes (like Scott): 60-90 minutes
For 100+ episodes: 2-3 hours
This is mostly API processing time. You don’t sit and watch. Start it running, go do other work, check back.
Common Pitfalls
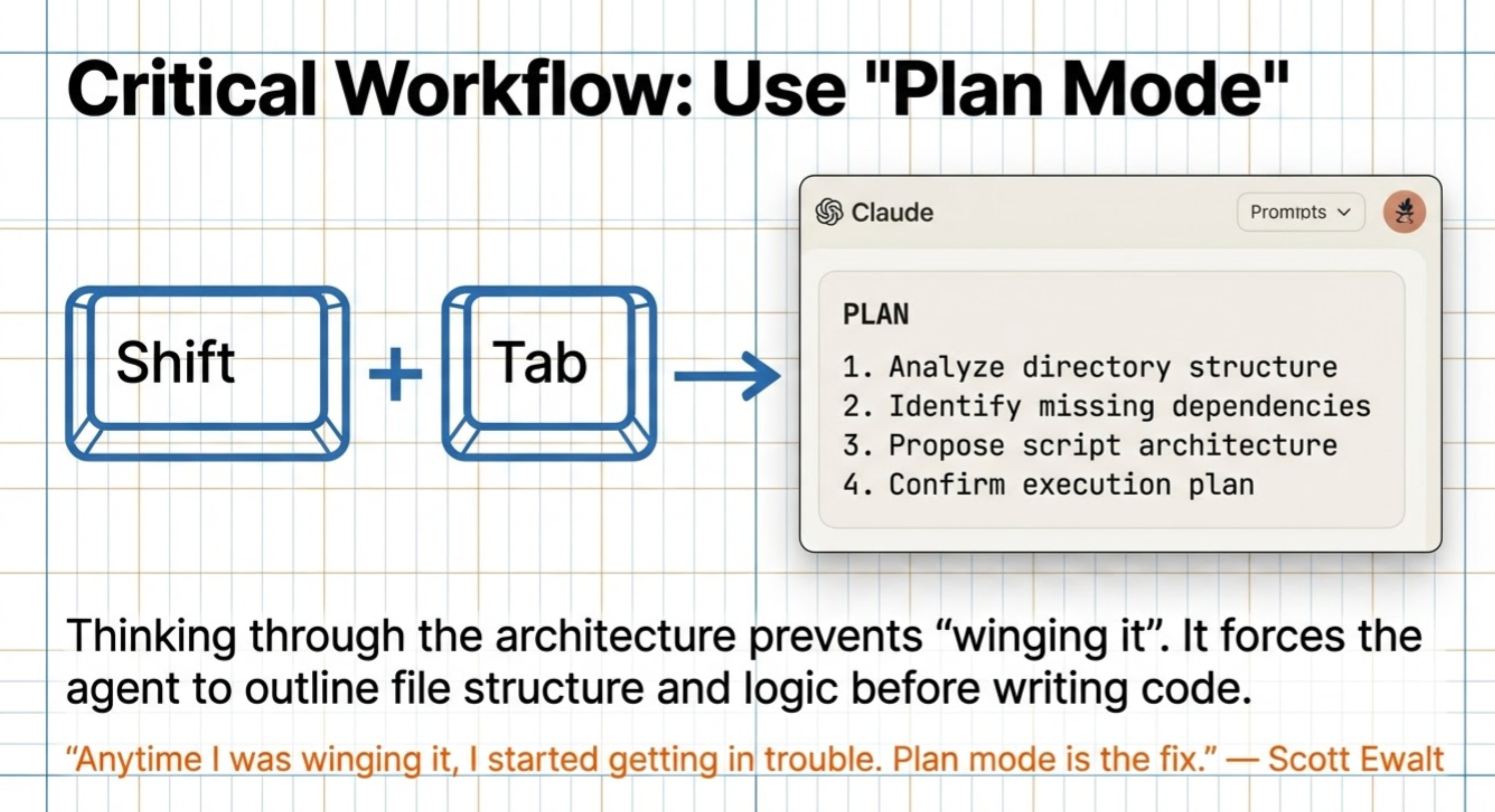
Pitfall 1: Starting without Plan Mode
Scott’s advice: “Use plan mode. Hit shift + tab before you start. The thinking through what you want beforehand is huge. Anytime I was winging it, I started getting in trouble.”
Pitfall 2: Not checking API credits
Make sure you have at least £20-30 in API credits on OpenAI.
Pitfall 3: Vague prompts
Don’t say: “Transcribe some podcasts for me”
Do say: “Transcribe all episodes from [specific podcast], save as markdown files organized by episode number”

Phase 3: Build the Vector Database (30-60 minutes)
Why You’re Doing This
Raw transcripts are hard to query effectively. If you just drop them into Claude and ask questions, you’ll get generic summaries, occasional hallucinations, no source citations, and vague insights you can’t use in battle cards.
A vector database enables:
Precise retrieval of relevant segments
Exact quotes with source attribution
No hallucinations (it only returns what’s actually in the transcripts)
Ability to query across all sources simultaneously
The Exact Prompt to Use
Now take all these transcript files and build a vector database.
I want to be able to query this database and get specific insights with exact quotes and source citations (episode numbers and context).
Use the Anthropic API for embeddings to ensure high-quality retrieval.
Here's my Anthropic API key: [YOUR API KEY]
Before you start building, use plan mode to show me the architecture.Testing Your Database
Ask a test question to verify it works:
Query this database: "What are the top use cases for AI in sales?"You should get back 3-5 relevant insights, each with an exact quote, episode number citation, and context around the quote.
Good result:
“Based on Episode 23, Scott mentioned: ‘Only 39% average quota attainment across sales teams.’ This was in the context of discussing why AI alone doesn’t fix broken sales processes.”
Bad result:
“AI can help with sales in many ways, including productivity improvements and better customer targeting.”
If you get the bad result, tell Claude Code: “These results are too generic. I need exact quotes from the transcripts with episode citations. Adjust the query prompts to return more specific excerpts.”
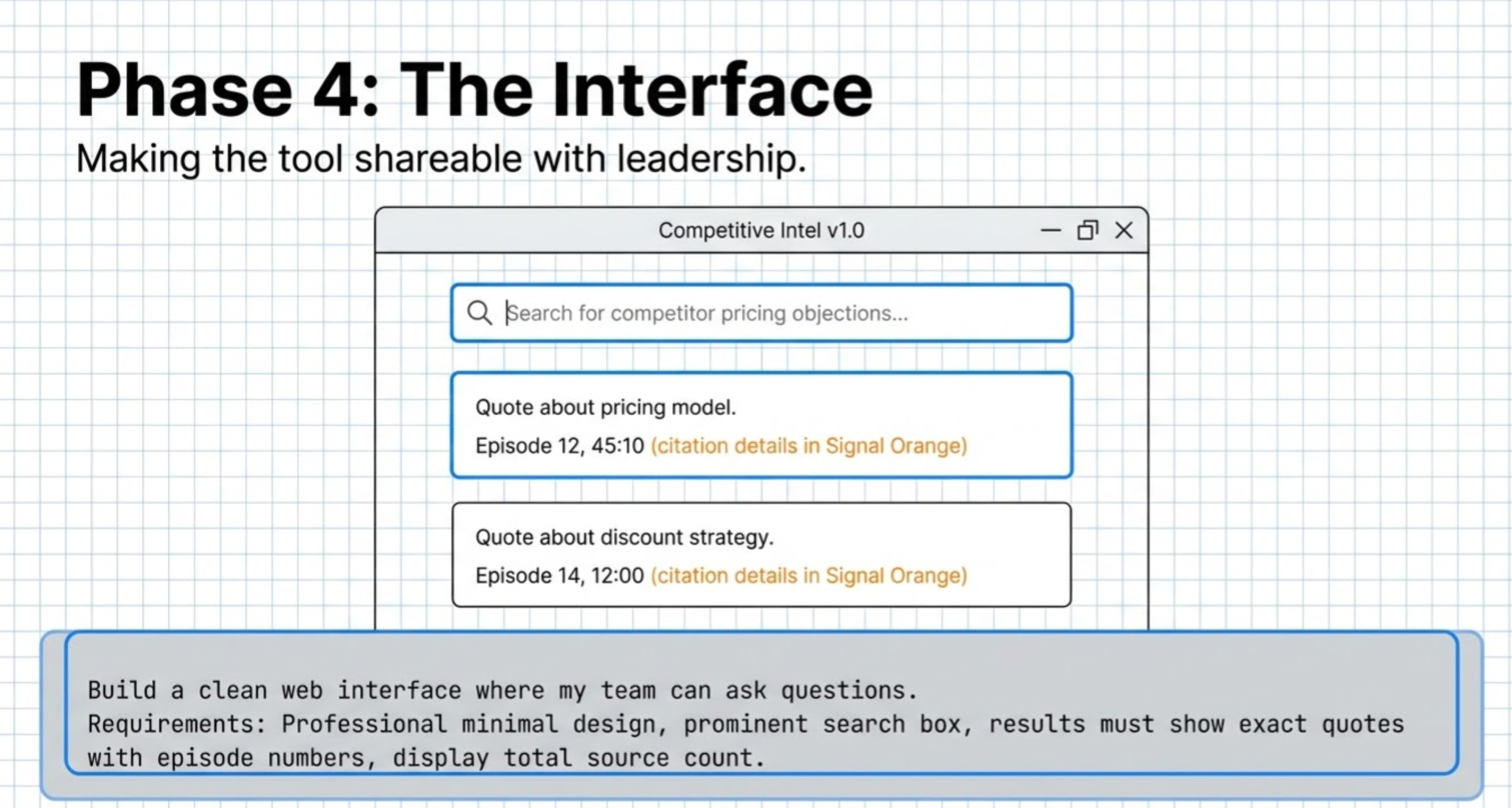
Phase 4: Build the Query Interface (60-90 minutes)
Why You Need This
Querying from the terminal works, but it’s not shareable with your team. You want a web interface where sales ops can ask questions, product marketing can research messaging, RevOps can pull competitive insights, and anyone can query without knowing how to use the terminal.
The Exact Prompt to Use
Build a clean web interface where my team can ask questions of this database and see results with source citations.
Requirements:
- Professional appearance (clean, minimal design)
- Search box prominently displayed
- Results show exact quotes with episode numbers
- Display which episodes are in the database (total count, hours of content)
- Show source attribution for every insight returned
- Make it look professional enough to demo to leadership
Use plan mode to show me the UI structure before building.Testing Your Interface
Test Query 1: Broad strategic question
“What is the consensus on how AI can be used best in GTM?”
Should return: Multiple perspectives, specific quotes, episode citations
Test Query 2: Specific tactical question
“What are common objections to AI in sales?”
Should return: Exact objections mentioned, who said them, episode context
Test Query 3: Trend validation
“Are experts recommending AI-first or AI-augmented approaches?”
Should return: Direct quotes showing expert opinions, episode references
Phase 5: Test with Real Competitive Questions (30 minutes)
Don’t skip this step. The quality of your system depends on how well it answers actual competitive questions your team needs.
Questions to Test
Competitive positioning:
“What messaging is [competitor] using in enterprise deals?”
“How does [competitor] position against legacy solutions?”
“What differentiation claims is [competitor] making about AI?”
Market intelligence:
“What objections are prospects raising about [product category]?”
“What pain points are customers citing most often?”
“How are industry experts describing the shift to [trend]?”
Buyer insights:
“What do buyers actually care about when evaluating [solution type]?”
“What gaps exist between vendor claims and buyer reality?”
“Which features do customers mention most in positive reviews?”
Phase 6: Scale Across Sources (Ongoing)
Once the system works for one podcast, scale it to create a genuine competitive moat.
Sources to Add Next
Competitor podcasts:
Add [COMPETITOR CEO NAME]'s podcast appearances to the database. Search for any podcast episodes where they were a guest, transcribe them, and add to the existing vector database.Earnings calls:
Transcribe these earnings call audio files and add them to the vector database. Tag them as source_type: "earnings_call" so I can filter queries by source.Customer reviews:
Take these customer review CSV files and add them to the vector database. Extract the review text and reviewer role. Tag as source_type: "customer_review".Your own sales calls:
Add these sales call transcripts from Gong to the vector database. Tag them as source_type: "sales_call" and include deal stage metadata.The Compounding Effect
Month 1: 91 podcast episodes analyzed
Month 3: 250+ sources (podcasts + earnings calls + reviews)
Month 6: 500+ sources (everything above + sales calls + conference talks)
Your competitive intelligence becomes a genuine moat. Competitors doing manual research can’t catch up.
Query Examples Across Sources
Cross-source validation:
“Compare what [Competitor] says in podcasts vs. what customers say in G2 reviews about their AI capabilities.”
Trend tracking:
“How has [Competitor]’s messaging evolved from Q1 to Q4 based on earnings calls and conference talks?”
Reality check:
“What gaps exist between [Competitor]’s claims in marketing and what our reps hear in competitive deals?”
Market intelligence:
“What pain points appear in both customer reviews AND sales call transcripts but no competitors address publicly?”

Automation: Set It and Forget It
Weekly Automation
Set the system to check for new content weekly:
Create a script that runs weekly to:
1. Check for new episodes on these podcast RSS feeds: [LIST]
2. Auto-transcribe any new episodes
3. Add them to the vector database
4. Send me a summary of what was added
Schedule this to run every Monday at 9am.Real-time Alerts
Create an alert system that notifies me when new transcribed content mentions:
- Our company name
- Our product categories
- Key competitive terms: [LIST]
Send alerts via email or Slack.Monthly Summary
Create a monthly report that analyzes:
- New sources added this month
- Most queried topics
- Trending themes across all sources
- Changes in competitor messaging
Generate as a PDF summary.
What This Costs (Reality Check)
Initial build (91 episodes like Scott):
OpenAI Whisper transcription: £15-25
Anthropic embeddings: £3-5
Total: ~£20-30
Monthly ongoing (assuming 20 new episodes/month):
Transcription: £3-5
Embeddings: £1-2
Total: ~£5-7/month
Compare to alternatives:
Competitive intelligence team (3 people): £300K+/year
CI software platforms: £20K-50K/year
Manual research time: 10-20 hours/week
ROI calculation:
Build time: 4 hours (one-time)
Monthly cost: £5-7
Saves: 10-20 hours/week of manual research
Enables: Always-on competitive intelligence
If you value your time at £100/hour, you save £1,000-2,000/week minimum.
Why This Window Is Closing
The current state: Most GTM teams don’t have competitive intelligence systems. They have people who manually research competitors when needed.
What’s changing: Tools like Claude Code just eliminated the engineering bottleneck. Your ops team can build this. This week.
The opportunity window: 6-12 months before this becomes table stakes.
Early movers get:
Time advantage - Compounding starts now while competitors debate
Capability advantage - Your team gains experience while others evaluate
Data advantage - Every month adds intelligence competitors can’t catch up to
The teams that move first will have systems analyzing hundreds of sources while competitors are still debating whether to hire a competitive intelligence analyst.
“If you have the vision, the tools are available and they’ll help you execute. The capability gap opening right now is teams that can build these systems internally will move 5x faster than teams waiting on vendors.”
— Scott Ewalt
The gap will be insurmountable. Build yours this week.
this is amazing, it's the first time I really see someone build really useful thing with AI