
GTM AI Podcast 11/26/25: Thanksgiving has nothing on AI, goodies before the holiday!

HAPPY THANKSGIVING WEEK!
I am truly, humbly grateful for all your support, insights, and how good you have been to me this last year of 2025. So many things to be grateful and your continued support is FOR SURE one of them.
Truly thank you.
If you like the newsletter and podcast, please share it and give me feedback or comment! Always love hearing from you.
As per usual, so many things happening, I wanted to make sure that I gave you the download on everything happening, because as always there is a ton and I try to make it consummable for you and easy to stay up to date.
As per usual, this is sponsored by the GTM AI Academy and AI Business Network.
I also created a NotebookLM already loaded with the research papers, articles, and information for todays newsletter you can access.
Without further ado, lets get into the GTM AI PODCAST!

You can go to Youtube, Apple, Spotify as well as a whole other host of locations to hear the podcast or see the video interview.
$40M in Dead Pipeline: The ICP Lie Most Revenue Teams Are Living
GTM AI Podcast Recap — Episode with Hussain Al Shorafa, CEO of Revic.ai
The Setup
Hussain Al Shorafa’s team walked into a customer engagement that should have gone sideways. The company had a sophisticated rev ops function. They’d invested in Six Sense, Demandbase, ZoomInfo, or the full modern GTM stack. They had smart people running the operation.
Revic’s assessment: 62% of the accounts this team was actively pursuing sat outside their actual ICP.
The customer’s response was predictable. They told Hussain to pound sand. His company was eighteen months old. Theirs had been running this motion for years with serious investment in data infrastructure. Who was this startup to tell them their targeting was broken?
Five months of friction followed. Revic kept showing evidence. The customer kept pushing back. Then something shifted.
The CRO was at dinner when an email came through, which was another lost deal. Hussain pulled up the platform. Revic had flagged that account from the beginning. The system’s assessment: this deal never had a real chance. The signals weren’t there. The fit wasn’t there.
The CRO asked the obvious question: where else is this true?
The answer: $40 million in active pipeline.
The Guest
Hussain Al Shorafa started on the technical side before making a hard pivot into sales. The catalyst was a Lakers-Trailblazers playoff game in 2000, Game 7, Kobe to Shaq for the alley-oop dunk. The sales guy who gave him the tickets had a lifestyle Hussain wanted. He decided to chase it.
What followed was fifteen-plus years progressing from individual contributor through sales leadership across public and private companies. He built teams. He hit numbers. He also watched the same dysfunction repeat everywhere he went.
Sales would bring market signal back to the organization. The organization would push back. Internal friction would make an already difficult job harder. The people closest to the customer would catch heat from functions that had less direct exposure to what buyers actually said and did.
Revic.ai came out of that frustration. The thesis: sales organizations generate enormous amounts of knowledge through customer interactions, but that knowledge evaporates constantly. Reps leave. Context disappears. The next person starts from scratch. What if you could capture that institutional memory and make it usable?
The Core Problem
Every sales organization has two real assets: the people and what those people know.
The people churn. Industry average says you’re looking at a nearly net-new sales organization every three years. That’s not a bug in the system, it’s the actual system. Reps get promoted, poached, burned out, or restructured. They leave.
When they leave, they take something with them that never gets captured in Salesforce notes or call recordings: context. The understanding of why deals worked. The pattern recognition that told them which accounts were real and which were theater. The instinct for which message landed with which persona and why.
Hussain made a point that stuck with me: the most valuable information he ever received as a rep came from peers. Not enablement decks. Not marketing messaging guides. Other reps telling him how they won, why they lost, what competitors showed up, what objections hit hardest. That peer knowledge was gold.
The problem is that peer knowledge lives in people’s heads. It gets shared in Slack threads that disappear. In hallway conversations that never get documented. In deal reviews that surface insights but don’t systematize them.
Revic’s approach is to ingest everything from CRM data, conversational intelligence recordings, email threads, data warehouse information and extract the patterns. Not just “we won at Company X” but the full context of why. Then correlate those patterns against a universe of 35 million tracked companies to surface where the same signals appear.
Why ICP Misalignment Is the Expensive Problem Nobody Fixes
The $40 million pipeline story illustrates something that’s true almost everywhere: stated ICP and actual ICP are rarely the same thing.
This happens for structural reasons, not because anyone is incompetent.
Product leadership made promises to VCs about total addressable market. Those promises created pressure to expand ICP definitions to prove the TAM exists. That expansion introduces complexity for sales teams who now have to figure out how to win in segments that might require different motions, different messaging, or different product capabilities.
Marketing operates on longer time horizons than sales. They’re building pipeline for quarters out while sales needs closable opportunities in the next 90 days. They sit between product and sales—two functions that historically don’t get along, trying to balance competing demands.
Sales sees direct market signal, but only from a narrow slice: the accounts that SDRs and marketing surfaced. That’s valid data. It’s also incomplete. A rep’s view of “the market” is really a view of “the market as filtered through our inbound and outbound targeting.”
Everyone operates with partial information. Everyone makes reasonable decisions from their vantage point. The aggregate result is that organizations pursue accounts that don’t fit, generate pipeline that won’t convert, and burn resources on deals that were never real.
The cascade from ICP misalignment touches everything downstream:
Marketing generates leads that sales can’t convert, creating pressure for more lead volume and higher pipeline coverage ratios
Some percentage of bad-fit deals close anyway, pulling engineering into feature work for edge-case customers
Customer success inherits accounts that should never have been won, spending disproportionate time on relationships that will ultimately churn
The churn creates pressure on new business to fill the gap, and the cycle accelerates
The worst case isn’t losing deals you shouldn’t have won. The worst case is winning them. That’s when the real cost compounds.
The Behavioral Similarity Insight
Traditional account targeting runs on firmographics. Industry. Company size. Revenue band. Geography. Employee count. These attributes tell you what a company is. They don’t tell you how a company behaves or what it’s ready to do.
Hussain gave an example that reframed how I think about account similarity.
Equifax and TransUnion should look similar by any standard firmographic model. Same industry. Direct competitors. Similar scale. If you won at one, conventional wisdom says the other is a natural next target.
Revic’s analysis said otherwise. Based on strategic priorities, hiring patterns, leadership tenure, and organizational signals, Equifax looked more like Intuit than TransUnion. The way they describe roles in job postings. The language they use in strategic communications. The types of people they’re bringing in. Behaviorally, Equifax and Intuit were running similar playbooks.
The implication for targeting: if you won at Intuit, Equifax might be a better next account than TransUnion, even though firmographics would point you in the opposite direction.
This extends to the person level. A VP of Sales title at a bank means something completely different than a VP of Sales title at an insurance company. Same words, different universe. But even within similar companies, individual indicators matter. Someone eighteen months into a role behaves differently than someone fifteen years in. One is likely a change agent looking to make their mark. The other is a maintainer protecting what’s already working.
Revic’s approach is to analyze these behavioral signals at scale:
Strategic imperatives surfaced through public communications, earnings calls, press releases
Hiring patterns that reveal how the organization thinks about problems based on role descriptions and team composition
Leadership tenure as a proxy for openness to change
Historical response to new technology based on observable adoption patterns
The goal is to match on behavioral similarity rather than categorical similarity. Two companies in different industries with aligned behaviors are often better targets than two companies in the same industry with divergent approaches.
The Data Convergence Opportunity
GTM teams complain about tool sprawl constantly. Too many platforms. Too much data. Too much noise. The complaints are legitimate—the overhead of managing a complex stack is real.
But Hussain made a point worth considering: every tool is a data source, and every data source is a dimension of signal. The problem isn’t having too many tools. The problem is not having a synthesis layer that correlates signal across all of them.
He drew a parallel to cybersecurity. In his previous work, he watched advanced security programs move from licensing a single threat intelligence provider to licensing all of them. The reasoning was straightforward: the cost of a security breach was so catastrophic that the marginal cost of additional signal sources was trivial by comparison. Better to have redundant coverage than to miss the one indicator that mattered.
The same logic applies to revenue, especially at higher ASPs. The value of converting a qualified account is significant enough that the cost of multiple data sources is easily justified. The historical constraint was synthesis—how do you make sense of all that signal? AI changes that equation.
One observation from Revic’s work across customers: intent data providers perform inconsistently. Not because the providers are bad, but because signal quality varies by industry, buying pattern, and how well the provider’s model matches your specific market.
The solution isn’t picking the “right” provider. The solution is ingesting multiple sources and letting your own conversion data tell you which signals actually correlate with wins for your organization. What works for one company might be noise for another. Your outcomes are the ground truth.
Connect
Hussain Al Shorafa — on Linkedin
Revic.ai — revic.ai
If this reframed how you think about ICP, pipeline quality, or account prioritization, share it with your revenue leadership team. The $40 million problem is more common than anyone wants to admit. Most teams just haven’t built the systems to see it yet.

The $20B Disconnect: Why AI Engineers Are Betting Against Unicorns (And What GTM Leaders Should Actually Build Instead)
What You’ll Learn
The gap between AI fundraising narratives and engineering reality just got quantified at a major conference. We’re analyzing three critical signals: a room full of LLM engineers voting a $20B company “most likely to fail,” OpenAI’s cofounder declaring agents won’t work for a decade, and Gemini 3’s demonstration that we’ve moved past chatbots into something requiring entirely different management models. This isn’t pessimism—it’s pattern recognition that separates winners from well-funded losers.
Source Material
The State of Play
The Conference Vote That Reveals Everything
At a major AI conference, a room full of engineers building LLM products voted Perplexity, valued at $20B, most likely to fail. Not a consumer product company. Not a hardware startup. A company processing 780M queries monthly with backing from top-tier VCs. The people who build this technology looked at the unit economics and voted “dead company walking.”
The math is brutal: Perplexity trades at 100x revenue while processing 0.2% of Google’s search volume. Every query burns LLM inference costs. Google serves most searches from cache for pennies. When Microsoft integrated ChatGPT into Bing with exclusive GPT-4 access and infinite marketing spend, they gained 0.6 percentage points in three years. DuckDuckGo has spent 17 years reaching 2.3% market share despite profitability since 2014.
Perplexity’s response? They launched Comet browser in July, made it free, and reviews say it’s better than Arc. This is the tell. They’re solving a distribution problem with product quality—the exact strategy that doesn’t work. Arc is beloved by users and hasn’t dented Chrome’s 65% market share. Browser wars ended when Google bundled Chrome with every service and defaulted it on Android. Google pays Apple $18B annually just to remain default on Safari.
From Chatbots to Agents (But Not Really)
Ethan Mollick’s Gemini 3 testing reveals we’ve crossed a threshold. Three years ago, we were impressed an AI could write a coherent poem about otters. Today, Mollick asked Gemini 3 to “show how far AI has come since this post by doing stuff,” and it built a fully interactive game—coding the engine, designing the interface, deploying it.
More significant: Mollick gave Gemini 3 a decade-old research directory full of files labeled “project_final_seriously_this_time_done.xls” and told it to “figure out the data and structure and get it ready to do a new analysis.” Then: “Write an original paper using this data. Do deep research on the field, make it about an important theoretical topic, conduct sophisticated analysis, write it up as if for a journal.”
The AI generated original hypotheses, created its own measurement methodology using NLP to compare crowdfunding descriptions mathematically, executed statistical analysis, and produced a 14-page formatted paper. Mollick’s assessment: “PhD-level intelligence” if defined as competent grad student work. But it had grad student weaknesses, statistical methods needed refinement, theorizing outpaced evidence, approaches weren’t optimal.
The critical shift: We’ve moved from “human who fixes AI mistakes” to “human who directs AI work.” Errors are now subtle judgment calls and human-like misunderstandings rather than hallucinations.
The Decade Reality Check
Andrej Karpathy, OpenAI cofounder and leader of the vibe-coding movement, delivered the counterpoint everyone’s avoiding: “They just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working.”
His timeline? A decade to work through these issues.
The compound error problem is real. Each AI action has roughly a 20% error rate. For a 5-step task, there’s only a 32% chance it gets every step right. The industry is building tooling that assumes fully autonomous entities collaborating in parallel while humans are useless—a future Karpathy explicitly rejects.
His critique: “The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless.” The con? Humans become useless, and AI slop becomes ubiquitous.
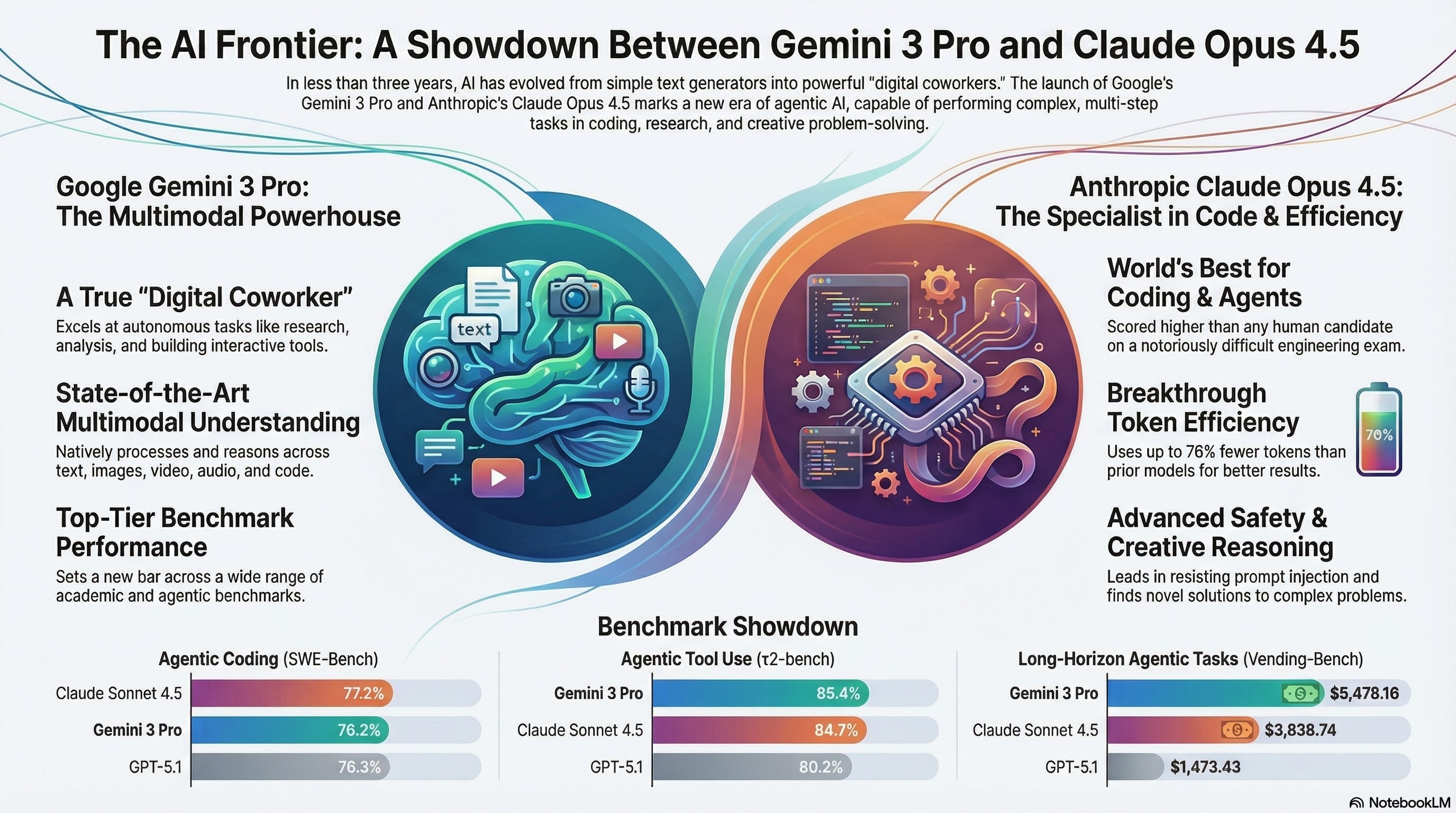
What These AI Model Updates Actually Mean for Your GTM Motion
The Three-Way Race and What Just Changed
Google just launched Gemini 3 Pro, Anthropic released Claude Opus 4.5, and both are significantly ahead of OpenAI’s GPT-5.1 on specific tasks that matter to revenue teams. Here’s what you’re looking at: The three bars on the left show how well each model can write and execute code autonomously, Claude wins at 77.2% success rate. The middle section shows how well they can use tools like web browsers, databases, and APIs to complete tasks, Gemini wins at 85.4%. The right section shows complex multi-step projects that require planning, execution, and course correction over many steps, Gemini completes these in fewer steps (6 vs Claude’s 9) but at higher cost ($5,478 vs $3,838). GPT-5.1 trails significantly, completing the same tasks at only $1,473 but presumably with more errors or simpler approaches.
Translation: What “Agentic” Actually Means for Your Team
Forget the technical terms, here’s what these capabilities enable. “Agentic coding” means the AI can build dashboards, automate workflows, create custom tools, and integrate systems without your team writing code. If your sales ops team needs a custom Salesforce report that pulls data from three sources and emails it weekly, these models can build that from a plain English request. “Agentic tool use” means the AI can operate your existing software stack all pulling customer data from your CRM, researching prospects on LinkedIn, updating spreadsheets, sending emails, and logging activities. The “long-horizon tasks” benchmark measures whether the AI can run a multi-day project like “analyze our Q3 pipeline, identify patterns in lost deals, create a presentation with recommendations, and draft follow-up emails to at-risk opportunities.”
The Economic Reality Behind the Performance Numbers
The benchmark differences look small: 77.2% vs 76.2% on coding tasks, but the cost structure is what matters for your P&L. Claude is optimized to use 76% fewer “tokens” (the units AI companies charge for) than previous models, which means it costs substantially less to run the same task. Gemini completes tasks faster and in fewer steps, but each step is more expensive. Think of it like shipping: Claude is the slower freight option that costs $3,838 per complex project, while Gemini is express shipping at $5,478 for the same result delivered faster. For use cases where you’re running hundreds or thousands of queries daily—sales email generation, customer support responses, lead research, Claude’s efficiency means your AI budget goes further. For use cases where speed and real-time response matter more than cost per query—live customer interactions, time-sensitive deal analysis, Gemini’s step efficiency wins.
Why OpenAI Falling Behind on Agents Changes Your Build vs Buy Calculus
GPT-5.1 completing long-horizon tasks at $1,473 vs Claude’s $3,838 initially looks attractive, but here’s the catch: it’s probably achieving that lower cost by doing less sophisticated work or requiring more human intervention to fix mistakes. Remember Karpathy’s compound error problem, if each step has a 20% failure rate, a 10-step project only succeeds 10.7% of the time. The lower cost might mean more steps with more errors, which means your team spends more time managing and correcting the AI. This matters because if you’ve built your GTM tech stack around OpenAI’s API, you now have competitors (using Gemini or Claude) who can automate more complex workflows with less human oversight. The gap in “agentic tool use” Gemini at 85.4%, Claude at 84.7%, GPT at 80.2% represents the difference between an AI that successfully completes 8.5 out of 10 multi-step tasks versus one that completes 8 out of 10. That extra half-task failure rate compounds across your entire operation.
The Strategic Implication: Model Selection Is Now a Competitive Advantage
Here’s what your competitors who understand this are doing: they’re not picking one model and standardizing on it. They’re building systems that route different tasks to different models based on what each does best. Use Claude for high-volume, cost-sensitive operations like email generation, outreach personalization, and content creation where token efficiency matters. Use Gemini for complex research tasks, multi-system integrations, and workflows where you need the AI to interact with multiple tools and data sources simultaneously. The companies treating AI models like interchangeable commodity infrastructure, swapping them based on task requirements and economic constraints, are building more cost-effective and capable GTM operations than companies locked into a single provider. The 1-2% performance differences in these benchmarks aren’t meaningful for model selection, but the 30-40% cost differences and speed-vs-efficiency tradeoffs absolutely are. Your AI infrastructure should be model-agnostic, because “best in class” is now task-specific, and the model that wins on Monday’s use case might lose on Wednesday’s.
Three Significant Trends in All Sourced Articles
1. The Distribution-Product Inversion: Excellence Without Access = Death
The Pattern:
Microsoft’s Bing + ChatGPT integration: 0.6% market share gain in 3 years despite exclusive GPT-4 access, infinite capital, and default Windows placement
Arc browser: Superior product, beloved users, negligible Chrome market share impact
Neeva: Founded by Google’s SVP of Ads with 15 years running search infrastructure, Sequoia/Greylock backing, sold for $184M after peaking at “a few million users”
DuckDuckGo: 17 years of profitability to reach 2.3% market share
Google’s Chrome dominance: Not won on quality but on bundling, default placement, and behavior training
The GTM Implication:
Product differentiation is table stakes, not a moat. Distribution architecture determines winners. Google pays $18B annually to remain default on Safari because they understand search isn’t about better answers—it’s about owning the default box on 4 billion devices.
For GTM leaders, this means:
Channel strategy beats product roadmap in determining survivability
Integration partnerships that provide default placement are worth more than feature superiority
Behavioral lock-in (training users to start in your interface) matters more than performance benchmarks
Bundling strategies should be prioritized over standalone product excellence
If you’re building a standalone AI product that requires users to change behavior or choose you over an existing default, you’re playing Perplexity’s game. The engineers voting at that conference have watched this movie before—they know how it ends.
2. The Unit Economics Trap: Inference Costs Create Inverse Scale Dynamics
The Numbers:
Perplexity: 780M queries monthly, 100x revenue multiple, LLM inference cost on every query
Google: 13.7B queries daily, cached results for pennies, costs drop with scale
Perplexity processes 0.2% of Google’s volume while burning cash on every interaction
The more Perplexity grows, the worse their margins get
The more Google grows, the better their margins get
The GTM Implication:
Traditional SaaS unit economics don’t apply to LLM-powered products. The economic model inverts: growth increases costs rather than decreasing them. This creates a structural disadvantage that compounds over time.
For GTM teams, this requires rethinking:
Customer acquisition cost vs. lifetime value calculations must account for per-query inference costs that don’t decrease with scale
Pricing models need to be inference-aware, not just value-based
Market sizing should prioritize scenarios where cached/repeated queries dominate (customer support, internal tools) over diverse one-off queries (general search)
Competitive dynamics favor incumbents with existing caching infrastructure and data flywheels
If your product burns inference costs on every interaction and competes with someone who caches results, you’re in a race where growth makes you less competitive. The instant any differentiated feature gains traction, Google (or Microsoft, or Amazon) copies it and ships to billions of users with better economics.
3. The Capability-Tooling Gap: We’re Building for a Future That’s 5-10 Years Away
The Evidence:
Karpathy: “The industry lives in a future where fully autonomous entities collaborate in parallel”
Current reality: 20% error rate per action → 32% success rate on 5-step tasks
Mollick’s Gemini 3 experience: PhD-level capability with grad student weaknesses requiring human direction and correction
Timeline disconnect: Industry tooling assumes AGI, Karpathy says decade minimum
The GTM Implication:
The most successful AI implementations right now aren’t fully autonomous—they’re collaborative. Mollick’s shift from “human who fixes AI mistakes” to “human who directs AI work” is the money quote.
This means GTM strategies should focus on:
Human-in-the-loop workflows as the actual product, not a temporary state
Management interfaces for AI work (like Antigravity’s Inbox concept) rather than “set it and forget it” agents
Transparency and checkpoints in AI execution to maintain control
Training customers to direct rather than deploy AI
Companies building for full autonomy are creating tooling that overshoots current capability by 5-10 years. Companies building for human-AI collaboration are creating products that work today. The difference in time-to-value is measured in years.
The compound error problem is real and unfixable with current architectures. A 20% error rate per action means your 10-step workflow has a 10.7% success rate. You can’t productize that without human oversight.
What This Means for Your GTM Motion
If You’re Selling AI Products:
Stop competing on model quality. Gemini 3, Claude Opus 4.5, GPT-5—the models are converging toward “good enough” across most use cases. The differentiation that matters:
Default placement in existing workflows: Can you be the AI that appears when someone opens Slack, Salesforce, or Gmail? That’s worth more than being 10% better at reasoning.
Pre-built distribution channels: Integration partnerships that give you access to established user bases beat viral growth tactics. Google didn’t win search by being better—they won by being everywhere.
Economically sustainable inference models: If your costs rise with usage while competitors’ costs fall, you’re structurally disadvantaged. Find use cases where repeated queries allow caching, or where inference costs are offset by high per-query value.
If You’re Building AI Features:
The “agentic” era requires different management primitives. Antigravity’s Inbox concept, where agents work asynchronously and ping humans when they need approval is the pattern to watch. You’re not building autonomous agents; you’re building collaborative tools that need:
Visibility into AI reasoning and decision-making
Permission models for high-stakes actions
Rollback capabilities when AI makes judgment errors
Learning loops where human corrections improve future performance
The companies winning aren’t removing humans from the loop—they’re optimizing the collaboration between human judgment and AI execution.
If You’re Setting GTM Strategy:
The Perplexity vote reveals what engineers see that VCs miss: structural advantages beat product excellence. Before you invest in differentiation, audit:
Your distribution moat: Do you own default placement, behavioral habits, or integration points that competitors can’t replicate?
Your unit economics at scale: Do your margins improve or degrade as you grow?
Your capability-tooling match: Are you building for the AI future that exists today or the one that might exist in 5 years?
Microsoft spent billions integrating the hottest AI in the world and gained 60 basis points in three years. If infinite capital and exclusive access moved the needle that little, what makes you think your product differentiation will matter more?
The Bottom Line
The gap between fundraising narratives and engineering reality is widening. A $20B valuation on 0.2% of market-leader volume, trading at 100x revenue with inverse unit economics, this is what happens when capital chases story over structure.
The three-year evolution from GPT-3 to Gemini 3 is real. We’ve moved from chatbots that write poems to agents that conduct PhD-level research, code their own tools, and autonomously execute complex workflows. But Karpathy’s decade timeline isn’t pessimism, it’s the gap between demonstration and productization.
The companies that will win aren’t building the best AI. They’re building distribution moats, sustainable unit economics, and collaboration models that work with today’s 20% error rates rather than tomorrow’s theoretical perfection.
The engineers voting at that conference understand something VCs are learning slowly: in technology, distribution isn’t everything, it’s the only thing. Product excellence is necessary but not sufficient. And building for a future that’s 5-10 years away means you’ll run out of runway before the future arrives.
The shift from “human who fixes AI mistakes” to “human who directs AI work” isn’t just a philosophical change—it’s the difference between companies that survive the inference cost curve and those that don’t.
If you like this please share!